Table of Contents
This article is part of an ongoing Natural Language Processing (NLP) course. In the previous lessons, we learned Lexical processing concepts and also worked on a project to build Spell Corrector. In this article, we will explore what syntactic processing is, how it works, and why it is important in NLP.
What is Syntactic Processing?
Syntactic processing is the process of analyzing the grammatical structure of a sentence to understand its meaning. This involves identifying the different parts of speech in a sentence, such as nouns, verbs, adjectives, and adverbs, and how they relate to each other in order to give proper meaning to the sentence.
Let’s start with an example to understand Syntactic Processing:
- New York is the capital of the United States of America.
- Is the United States of America the of New York capital.
If we observe closely, both sentences have the same set of words, but only the first one is grammatically correct and which have proper meaning. If we approach both sentences with lexical processing techniques, we can’t tell the difference between the two sentences.
Here, comes the role of syntactic processing techniques which can help to understand the relationship between individual words in the sentence.
Difference between Lexical Processing and Syntactic Processing
Lexical processing aims at data cleaning and feature extraction, by using techniques such as lemmatization, removing stopwords, correcting misspelled words, etc. However, in syntactic processing, our aim is to understand the roles played by each of the words in the sentence, and the relationship among words and to parse the grammatical structure of sentences to understand the proper meaning of the sentence.
How Does Syntactic Processing Work?
To understand the working of syntactic processing, lets again start with an example.
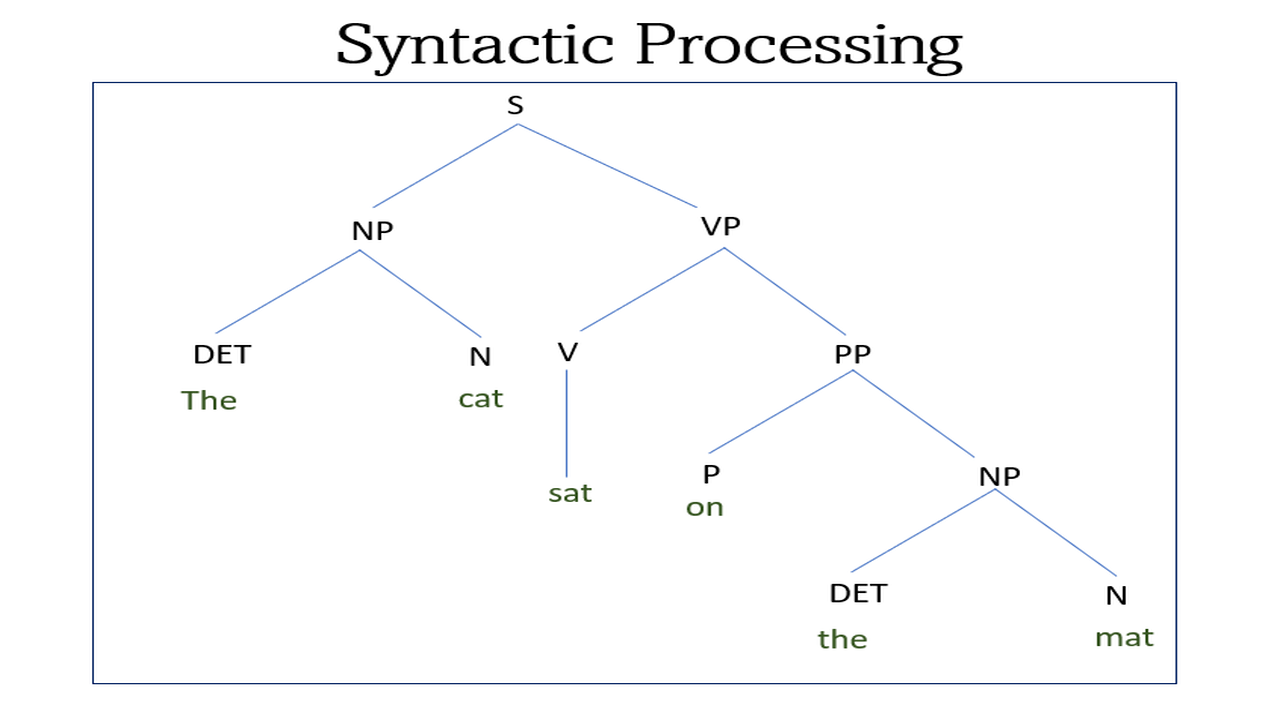
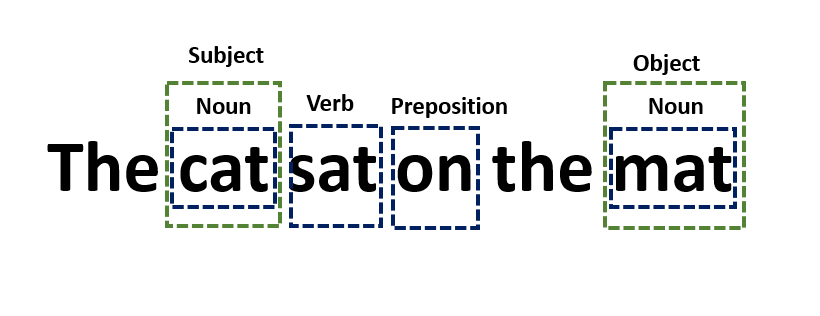
For example, consider the sentence “The cat sat on the mat.” Syntactic processing would involve identifying important components in the sentence such as “cat” as a noun, “sat” as a verb, “on” as a preposition, and “mat” as a noun. It would also involve understanding that “cat” is the subject of the sentence and “mat” is the object.
Syntactic processing involves a series of steps, including tokenization, part-of-speech tagging, parsing, and semantic analysis.
Tokenization is the process of breaking up a sentence into individual words or tokens. Part-of-speech (PoS) tagging involves identifying the part of speech of each token. Parsing is the process of analyzing the grammatical structure of a sentence, including identifying the subject, verb, and object. The semantic analysis involves understanding the meaning of the sentence in context.
There are several different techniques used in syntactic processing, including rule-based methods, statistical methods, and machine learning algorithms. Each technique has its own strengths and weaknesses, and the choice of technique depends on the specific task and the available data.
In the subsequent lessons, we will learn the concept of parsing and different parsing techniques, PoS Tagging, and semantic analysis.
Why Is Syntactic Processing Important in NLP?
Syntactic processing is a crucial component of many NLP tasks, including machine translation, sentiment analysis, and question-answering. Without accurate syntactic processing, it is difficult for computers to understand the underlying meaning of human language.
Syntactic processing also plays an important role in text generation, such as in chatbots or automated content creation. By understanding the grammatical structure of a sentence, computers can generate more natural and fluent textual content.
Conclusion
Syntactic processing is a fundamental task in NLP, which involves analyzing the grammatical structure of a sentence to understand its meaning. It is a crucial component of many NLP tasks specifically text generation and machine translation, and its accuracy is essential for computers to understand complex human language.
