Table of Contents
Natural Language Processing (NLP) is a branch of Artificial Intelligence (AI) that deals with the interaction between human language and computers. One of the most important tasks in NLP is syntactic analysis, which involves analyzing the structure of sentences and phrases in order to extract meaning from them. The first level of syntactic analysis is Part-of-Speech (POS) tagging.
In this article, we will discuss what part of speech tagging is, how it works, different types of part of speech tagging techniques, and how to perform part of speech tagging in Python.
1. What is Part of Speech Tagging in NLP?
Part of speech tagging involves assigning a grammatical category or “tag” to each word in a sentence, such as a noun, verb, adjective, adverb, or preposition.
Assigning tags not only helps in determining each word’s role in the sentence but also helps in disambiguating words with multiple possible meanings.
Part of speech tagging is a fundamental task in syntactic analysis, as all subsequent parsing techniques use part-of-speech tags to parse the sentence.
Part of speech tagging is used to analyze text documents, perform sentiment analysis, and extract useful information from the text.
2. How Does Part of Speech Tagging Work?
Part of speech tagging involves labeling each word in a sentence with its corresponding part of speech, such as noun, verb, adjective, preposition, etc.
The process of Part of speech tagging begins with tokenizing the input text into individual words. After tokenizing the text, each word is assigned a part of the speech tag based on its context in the sentence.
For example, consider the sentence “Ok Google, where can I get the permit to work in Australia?” The word “permit” can potentially have two POS tags: noun and verb.
Whereas in the phrase “I need a work permit,” the correct tag for “permit” is “noun,” while in the phrase “Please permit me to take the exam,” the correct tag for “permit” is “verb.”
Assigning the correct POS tags helps us better understand the intended meaning of a phrase or sentence.
There is a total of 36 POS tags in the Penn Treebank corpus in the Natural Language Toolkit (NLTK), a popular Python library for NLP.
However, it is not necessary to memorize all of them, as some are more common than others. It is recommended to focus on the most commonly used tags, such as noun (NN), verb (VB), adjective (JJ), Preposition (IN), and adverb (RB).
It is important to be familiar with them if you plan to use NLTK for NLP tasks. In short, POS tagging is a crucial part of syntactic processing, and understanding the common POS tags can help you become a better NLP practitioner.
3. Why is Part of Speech Tagging Important in NLP?
POS tagging is an important task in NLP because it helps computers to understand human language better.
By analyzing the part of speech of each word in a sentence, computers can determine the meaning of the sentence and perform various operations, such as sentiment analysis, text classification, and language translation.
4. Different Part of Speech Tagging Techniques
There are mainly three types of POS tagging techniques in NLP.
1. Lexicon-based POS Tagging
The lexicon-based approach to POS tagging utilizes a statistical algorithm that is based on the frequency of occurrence of each word in a training corpus. This approach assigns the most frequently occurring POS tag to each word in the text. However, this approach is not capable of handling unknown or ambiguous words, and it may result in incorrect tagging for such words. For example:
- I went for a run/NN
- I run/VB in the morning
Consider the word “run” which can be used as a noun or a verb. In the first sentence “I went for a run,” “run” is used as a noun, while in the second sentence “I run in the morning,” “run” is used as a verb. The lexicon-based approach will tag the word “run” based on the highest frequency tag, which is likely to be a verb. This means that the lexicon tagger will incorrectly tag “run” as a verb in the first sentence, even though it is used as a noun.
This limitation of the lexicon-based approach highlights the need for more advanced POS tagging techniques, such as probabilistic and rule-based methods, which can handle unknown or ambiguous words and provide more accurate tagging.
2. Rule-based POS Tagging
Rule-based POS tagging involves creating a set of rules based on grammatical structures and applying these rules to assign part-of-speech tags to each word in a sentence. Consider the example shown in the lexicon-based approach, if there’s a rule that is applied to the entire text, such as,
‘replace VB with NN if the previous tag is DT‘,
or
‘tag all words ending with ing as VBG‘,
By using the above two rules, the tagging problem of the lexicon approach can be corrected.
In the next article, we will implement a lexicon and rule-based POS tagger in Python.
3. Probability-based (Stochastic) POS Tagging
Probabilistic POS tagging involves using statistical models to assign the most likely part of speech tag to each word in a sentence. This technique is based on the assumption that certain parts of speech are more likely to occur together in a sentence than others.
The most common form of stochastic POS tagging algorithm is the Hidden Markov Model which we will study in a separate article.
Now, let’s try to understand the idea of probability-based POS tagging.
To better understand the process of POS tagging using probabilistic methods, it is helpful to review two key concepts from Bayes’ theorem and the chain rule of probability.
Suppose you have two features, denoted as X = (x1, x2), and a binary target variable y with two possible classes: 0 and 1. According to Bayes’ theorem, the probability of a point (x1, x2) belonging to class 1 can be calculated as follows:
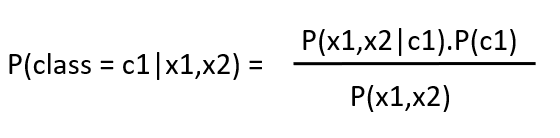
The chain rule of probability states that the joint probability of multiple events can be expressed as the product of their individual probabilities.
In the context of POS tagging, we can apply a similar idea to assign POS tags to sequences of words.
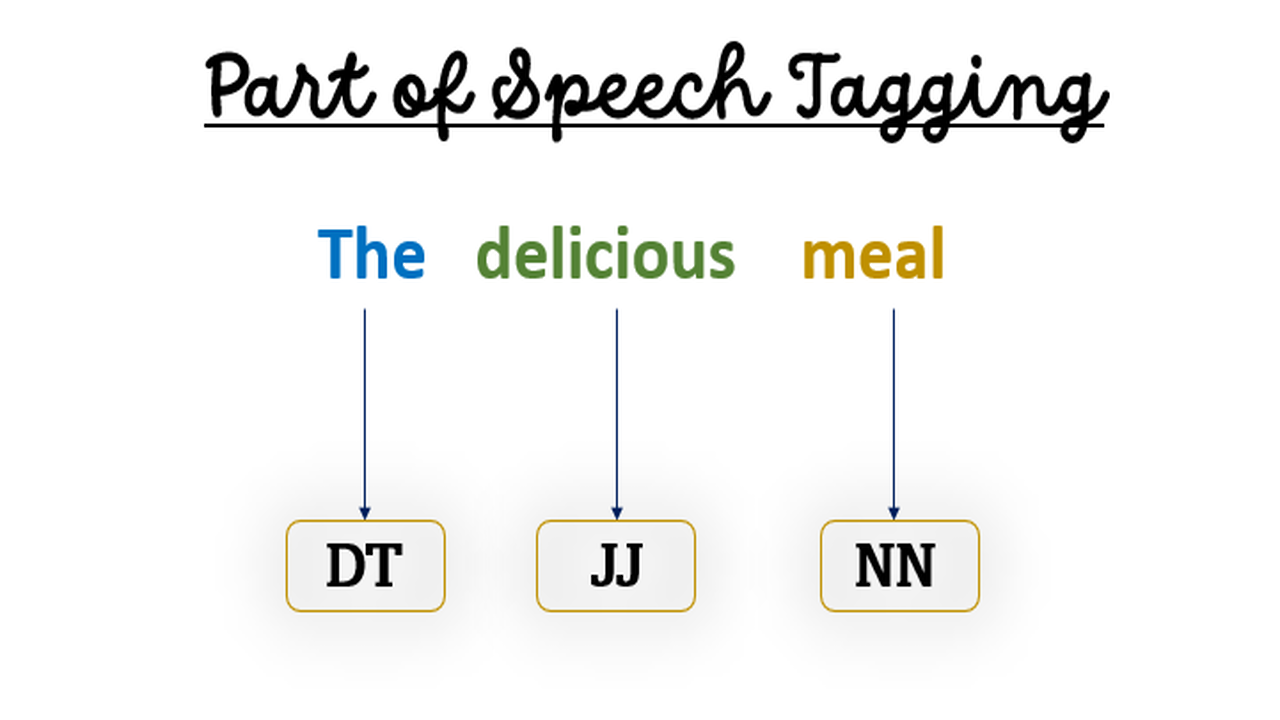
For example, consider the word sequence “The delicious meal” and the possible POS tag sequences of (DT, JJ, NN), (DT, NN, JJ), and (JJ, DT, NN).
We can now compute the probability of each tag sequence by multiplying the probability of each tag given the previous tag(s).
For instance, the probability that the tag sequence is (DT, JJ, NN) can be computed by multiplying the probability of the tag “DT” given the context of the previous tag being the start of the sentence, the probability of the tag “JJ” given the previous tag “DT”, and the probability of the tag “NN” given the previous tags “DT” and “JJ”.
The probability that the tag sequence is (DT, JJ, NN) can be computed as:
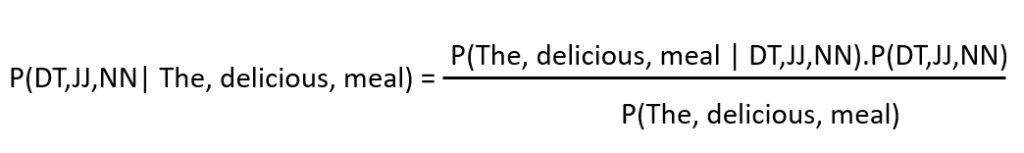
To perform stochastic parsing, we aim to identify the most probable sequence of POS tags for a given phrase.
Let’s take the example of the phrase “The delicious meal” and assume that we are working with three possible POS tags: Determinant (DT), Adjective (JJ), and Noun (NN).
Each word in the phrase can be assigned any of the three possible POS tags, resulting in 3x3x3= 27 possible tag sequences. However, for simplicity, we will consider only three possible tag sequences:
- (DT, JJ, NN)
- (DT, NN, JJ)
- (JJ, DT, NN)
Our goal is to find the maximum value of the probability of the tag sequence given the observation sequence (i.e., the phrase “The delicious meal”) among the possible tag sequences.
We will begin with the first tag sequence: (DT, JJ, NN).
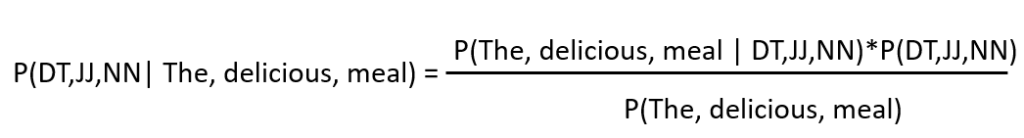
By applying the chain rule of probability, we can expand the terms on the right-hand side.

In stochastic parsing, we use an important assumption known as the Markov assumption, which is based on the concept of a Markov process.
In brief, a Markov process is a probabilistic model that describes how a system transitions from one state to another over time. In the context of POS tagging, the states are the possible POS tags.
The Markov assumption in POS tagging states that the probability of a state (i.e., a POS tag) depends only on the probability of the previous state leading to it.
For example, in a tag sequence of (DT, JJ, NN), the probability that a word is tagged as NN depends only on the previous tag JJ and not on DT.
Another simplifying assumption made in stochastic parsing is that the probability of a word being assigned a certain tag depends only on that tag and not on any other tags.
For instance, the probability of the word “the” being assigned the tag DT, denoted as P(the|DT), depends solely on DT and not on any of the other tags JJ or NN.
Performing POS Tagging using NLTK in Python
NLTK (Natural Language Toolkit) is a popular library in Python for performing various NLP tasks such as text processing, including POS tagging.
Before performing POS tagging using NLTK in Python, we need to install the NLTK library. Open your command prompt or terminal and run the following command:
pip install nltk
Now after installing nltk, let’s proceed to perform POS tagging using NLTK in Python.
import nltk
nltk.download('averaged_perceptron_tagger')
text = "John loves Mary"
tokens = nltk.word_tokenize(text)
pos_tags = nltk.pos_tag(tokens)
print(pos_tags)In this example, we first import the NLTK library and download the averaged perceptron tagger. Then we define a text string and tokenize it into individual words.
Finally, we use the pos_tag function from NLTK to assign POS tags to each word in the text.
The output of the code above will be:
[('John', 'NNP'), ('loves', 'VBZ'), ('Mary', 'NNP')]Each word in the text is now labeled with its corresponding part of speech tag.
Conclusion
Parts of speech tagging is an essential task in natural language processing that involves labeling each word in a sentence with its corresponding part of speech tag. It helps computers to better understand human language, which is crucial in various NLP applications.
In this article, we have discussed what POS tagging is, how it works, different techniques for performing POS tagging, and finally we have shown how to perform POS tagging in Python using the NLTK library.
FAQs
1. What is part of speech tagging with example?
Ans 1. Part of speech tagging is the process of labeling each word in a text document with its corresponding part of speech, such as noun, verb, adjective, preposition, etc. For example, part of speech tagging for the phrase “the delicious meal” is (DT,JJ,NN) where the->DT(Determiner), delicious->JJ(Adjective), and meal ->NN(Noun).
2. What is part of speech tagging used for?
Ans 2. Some of the important applications of part of speech tagging in NLP are sentiment analysis, text classification, language translation, and named entity recognition.
3. Can part of speech tagging be used for speech recognition?
Ans 3. Yes, part of speech tagging can be used for speech recognition. However, in speech recognition, the input is typically a stream of audio, which needs to be converted to text using speech recognition algorithms before part of speech tagging can be applied.
4. Can part of speech tagging be used for languages other than English?
Ans 4. Yes, part of speech tagging can be used for languages other than English. However, the accuracy of POS tagging may vary depending on the language and the availability of training data.
5. What are the different types of parts of speech tags?
Ans 5. The different types of parts of speech tags include noun (NN), verb (VB), adjective (JJ), adverb (RB), preposition (IN), conjunction (CC), pronoun (PRP), and interjection (UH).