
Table of Contents
If you’re looking to predict numerical values based on input data in machine learning, then understanding linear regression is very critical.
Linear Regression uses statistical analysis to establish a relationship between a dependent variable (y) and one or more independent variables (x).
In this article, we’ll break down the concept of linear regression in a more understandable way and explain how it works. We’ll also discuss some of its applications, limitations, and assumptions, so you can better understand how to use it in your projects.
But before proceeding to understand Linear regression, we recommend visiting this site to brush up on your knowledge of straight lines in coordinate geometry.
Understanding Linear Regression
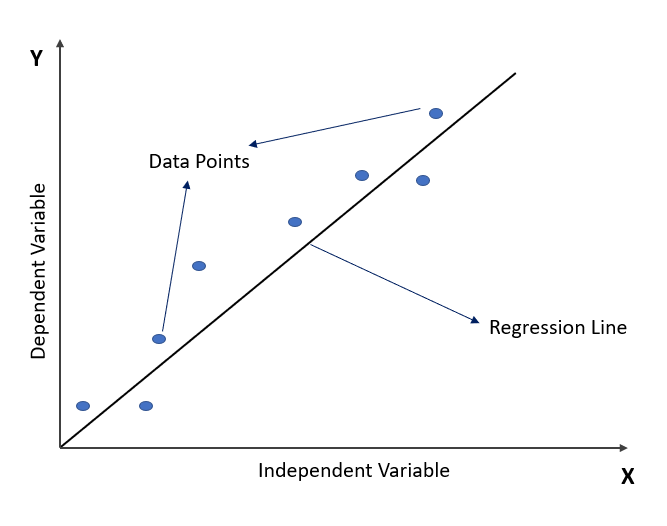
Linear regression is essentially a way of finding the best-fit line that describes the relationship between two or more variables. The goal is to use this line to predict future values of the dependent variable, based on the independent variables.
The equation for a linear regression line is that of a straight line in coordinate geometry i.e., y = mx + b, where m is the slope of the line, b is the y-intercept, and x is the independent variable.
Types of Linear Regression
There are two types of linear regression: simple and multiple.
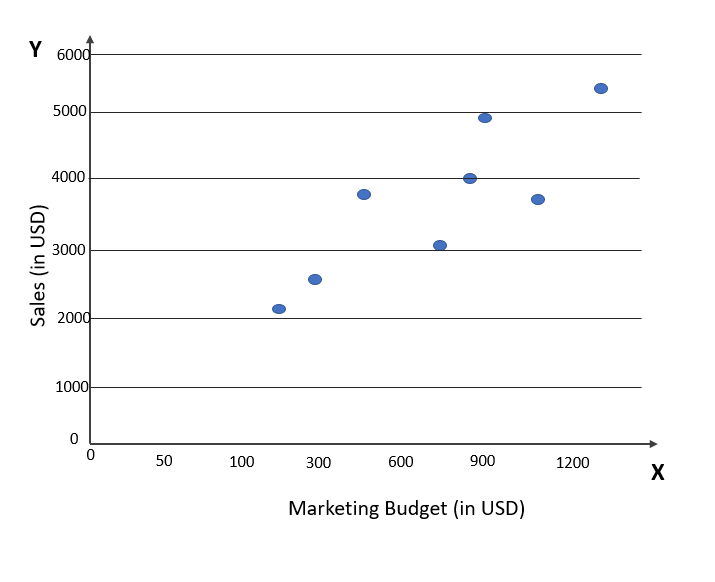
- Simple Linear Regression (SLR): In simple linear regression, there is only one independent variable for predicting a single continuous dependent variable. For example, the regression problem of predicting sales based on the marketing budget. The formula for SLR is given below:
Y = a0 + a1x + e
where,
a1 = slope or linear regression coefficient,
a0 = intercept of the line,
e = error term
2. Multiple Linear Regression (MLR): In simple linear regression, there is more than one independent variable for predicting a single continuous dependent variable. For example, the regression problem of predicting sales based on pending on three channels i.e., TV, Radio, and Newspaper. The formula of linear regression is now changed to the below form.
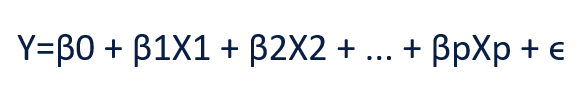
Here, B1,B2,…Bp are the other factors or independent variables which are required to predict dependent variable Y
Now, the model fits a hyperplane instead of a line in the case of MLR.
How Linear Regression Works
To determine the best-fit line for a given set of data, linear regression uses the method of least squares. This involves calculating the values of the slope and y-intercept that minimize the sum of the squared distances between the actual and predicted values.

The accuracy of the linear regression model depends on several factors, such as the quality and quantity of the data, the choice of independent variables, and the assumptions made about the relationship between the variables.
To ensure that the model is accurate, it’s important to carefully select the independent variables and perform exploratory data analysis to ensure that the assumptions are met.
Assumptions of Linear Regression
To ensure that the results of the linear regression analysis are reliable and accurate, four key assumptions must be met:
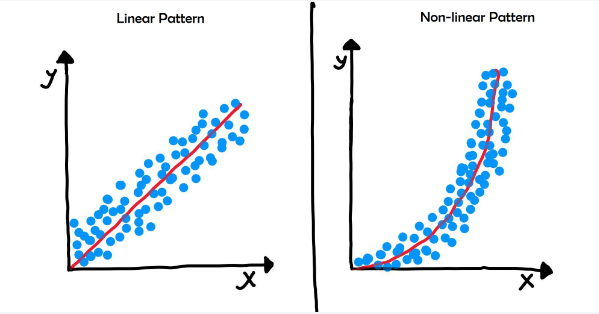
1. Linearity: The relationship between the dependent variable and the independent variable(s) should be linear. In other words, the relationship should be represented by a straight line on a graph.
2. Independence: The observations used to make predictions should be independent of one another. This means that the value of one observation should not be influenced by the value of another observation.
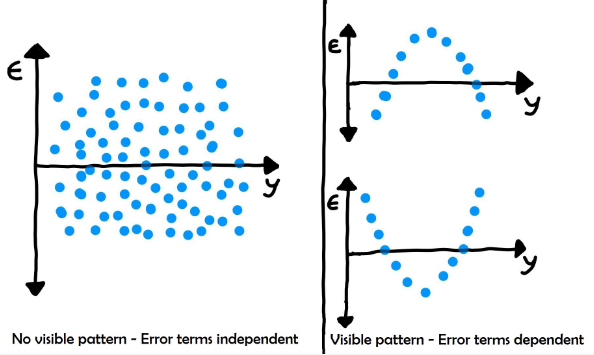
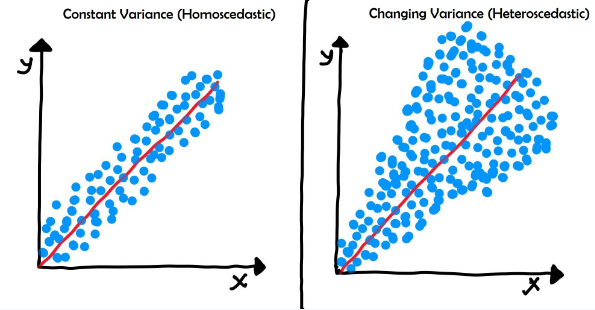
3. Homoscedasticity: The variance of the errors (or residuals) should be constant across all levels of the independent variable. In simpler terms, this means that the size of the errors should be consistent across the entire range of the independent variable.
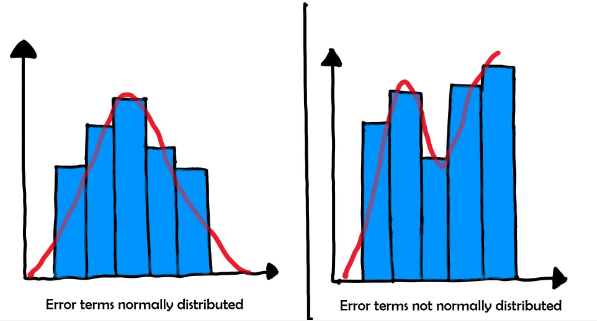
4. Normality: The errors should be normally distributed, meaning that they should follow a bell-shaped curve with a mean of zero.
If any of these assumptions are not met, the results of the linear regression analysis may be biased or inaccurate.
Therefore, it’s crucial to check that these assumptions are met before using linear regression to make predictions.
By doing so, we can create reliable and accurate machine-learning models that can help us make better decisions.
Strengths and Limitations of Linear Regression
Linear regression has several strengths that make it a popular choice for machine learning projects. It’s a simple and easy-to-understand method, and the coefficients of the linear regression equation have a clear interpretation. It’s also flexible, allowing for use with both continuous and categorical independent variables.
However, there are also some limitations to linear regression. One is that it assumes that the relationship between the variables is linear. If the relationship is nonlinear, then linear regression may not be the best choice.
Another limitation is that it’s sensitive to outliers, which can significantly impact the accuracy of the model.
Finally, linear regression requires certain assumptions about the relationship between the variables to be met, and if these assumptions aren’t met, then the accuracy of the model may be compromised.
Conclusion
Linear regression is a powerful tool in machine learning that can be used to predict numerical values based on input data. It’s important to understand how it works and what its strengths and limitations are before using it in your own projects.
By carefully selecting your independent variables, performing exploratory data analysis, and understanding the assumptions involved, you can create accurate and effective machine learning models using linear regression.
FAQs
1. What is linear regression, and what is it used for in machine learning?
Linear regression is a statistical technique used to establish a relationship between a dependent variable and one or more independent variables. It’s used in machine learning to predict numerical values based on input data.
2. What are the assumptions of linear regression?
There are four important assumptions of linear regression: linearity, independence, homoscedasticity, and normality. These assumptions are necessary to ensure that the results of the analysis are reliable and accurate.
3. What is the difference between simple and multiple linear regression?
In simple linear regression, there is only one independent variable, while in multiple linear regression, there are two or more independent variables. The dependent variable is always continuous in both cases.
4. How do you determine the accuracy of a linear regression model?
There are several metrics used to determine the accuracy of a linear regression model, including mean squared error (MSE), root mean squared error (RMSE), and R-squared. These metrics measure the difference between the predicted values and the actual values.
5. How do you select the independent variables for a linear regression model?
The selection of independent variables depends on the problem at hand and the available data. In general, it’s important to select variables that are relevant to the problem and have a strong correlation with the dependent variable.
6. What are some applications of linear regression in machine learning?
Linear regression is used in a variety of applications in machine learning, including finance, economics, engineering, and medical research. It’s used to predict stock prices, analyze risk, estimate the returns on investment portfolios, study the relationship between variables such as income and job satisfaction, predict the behavior of structures and systems, and study the relationship between risk factors and diseases.
7. What are some limitations of linear regression?
Linear regression assumes that the relationship between the variables is linear, and if the relationship is nonlinear, then linear regression may not be appropriate. It’s also sensitive to outliers, which can significantly impact the accuracy of the model. Finally, linear regression requires certain assumptions about the relationship between the variables to be met, and if these assumptions aren’t met, then the accuracy of the model may be compromised.
8. What is the difference between correlation and regression?
Correlation is a measure of the strength and direction of the relationship between two variables, while regression is a method for predicting the value of one variable based on the value of another variable.
9. What is the purpose of the intercept in linear regression?
The intercept in linear regression represents the value of the dependent variable when all the independent variables are equal to zero. It’s often interpreted as the baseline or starting point for the dependent variable.
10. How do you handle missing data in linear regression?
Missing data can be handled in several ways, including imputation (replacing missing values with estimated values) or deletion (removing observations with missing values). The best approach depends on the amount and nature of the missing data.
11. What is the difference between parametric and nonparametric regression?
Parametric regression assumes a specific form for the relationship between the variables, while nonparametric regression makes no assumptions about the form of the relationship. Nonparametric regression is often used when the relationship between the variables is nonlinear or the data is not normally distributed.
12. How do you choose between linear regression and other regression models?
The choice of regression model depends on the nature of the data and the problem at hand. Linear regression is often a good choice when the relationship between the variables is linear, but other models may be more appropriate for nonlinear relationships or when there are interactions between the variables.
By understanding these frequently asked questions about linear regression, you can be better prepared for a machine learning interview and have a better understanding of how linear regression can be used to make predictions and solve problems in various fields.
13. What is the difference between ridge regression and lasso regression?
Ridge regression and lasso regression are two types of regularized regression that are used to handle multicollinearity and prevent overfitting. Ridge regression adds a penalty term to the loss function that shrinks the coefficients towards zero, while lasso regression adds a penalty term that sets some of the coefficients to exactly zero.
14. How do you check for multicollinearity in linear regression?
Multicollinearity is a problem that can occur when two or more independent variables are highly correlated with each other. It can lead to unstable coefficients and inaccurate predictions. Multicollinearity can be checked by calculating the correlation matrix of the independent variables or by using variance inflation factor (VIF) values.
15. What is the difference between the residual and the error in linear regression?
The residual is the difference between the predicted value and the actual value of the dependent variable, while the error is the difference between the true value and the actual value of the dependent variable. The residual is a measure of the accuracy of the model, while the error is a measure of the accuracy of the predictions.
16. How do you interpret the coefficients in linear regression?
The coefficients in linear regression represent the change in the dependent variable for a one-unit increase in the corresponding independent variable, holding all other variables constant. The sign of the coefficient indicates the direction of the relationship, while the magnitude of the coefficient indicates the strength of the relationship.
17. How do you handle outliers in linear regression?
Outliers are data points that are significantly different from the other data points and can significantly affect the accuracy of the model. Outliers can be handled by removing them from the dataset, transforming the data, or using robust regression methods that are less sensitive to outliers.