
Table of Contents
Supervised machine learning involves training a model using a dataset that contains known label values to predict new labels based on a set of features. During the training process, the model learns to map the features to the known labels to create a general function that can predict the labels of new data points.
This function can be represented as y=f(x), where x is a vector of feature values and y is the label to be predicted.
The ultimate objective of training the model is to find a function that accurately calculates the labels from the given features.
This is achieved by applying a machine learning algorithm that adjusts the function to fit the feature values with the known labels from the training dataset.
This tutorial focuses on regression, where we will use a real-time case study on a bike-sharing scheme to predict the number of bike shares based on weather conditions and seasonality.
About Dataset
The initial stage of any machine learning project involves examining the dataset that will be utilized to train a model. This examination aims to comprehend the associations between the dataset’s attributes, particularly any potential connections between the features and the label that the model will attempt to predict.
In this project, we will be using London Bike Sharing Dataset available on Kaggle. The London Bike Sharing dataset is the historical data for bike sharing in London Powered by TfL Open Data.
Bike-sharing systems are a convenient way of renting bicycles, where the rental process is automated through a network of kiosks located throughout a city.
This allows people to rent a bike from one location and return it to another place as needed. With over 500 bike-sharing programs available worldwide, the data generated by these systems has become a valuable resource for researchers.
The bike-sharing system data includes information on the duration of travel, departure and arrival locations, and time elapsed, which makes it an attractive resource for studying mobility patterns within a city. Essentially, the bike-sharing systems act as a sensor network that can be utilized for research purposes.
Let’s start by loading the bike-sharing data as a Pandas DataFrame and viewing the first few rows.
import pandas as pd
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
# load the training dataset
bike_data = pd.read_csv('london-bike-sharing-dataset/london_merged.csv')
bike_data.head()
The dataset has the following columns:
- timestamp: Representing timestamp of bike share
- cnt: Representing total number of bike shares
- t1: The temperature in celsius.
- t2: The apparent (“feels-like”) temperature in celsius.
- hum: The humidity level
- wind_speed: The windspeed
- weather_code: A categorical value indicating the weather situation (1:clear, 2:mist/cloud, 3:light rain/snow, 4:heavy rain/hail/snow/fog)
- is_holiday: A binary value indicating whether or not the day is a holiday
- is_weekend: A binary value indicating whether or not the day is a weekend
- season: A numerically encoded value indicating the season (1:spring, 2:summer, 3:fall, 4:winter)
In this dataset, cnt represents the dependent variable i.e., label (the y value) our model must be trained to predict. The other columns are potential features (x values).
Now, let’s look into the number of records in the dataset and the datatype of each column. For this, we will use info() function in the pandas data frame.
bike_data.info()

From the above results, it is evident that there are no missing values in the dataset and the columns have a correct mapping with the datatype. A total of 17413 records are present in the dataset in which 8 columns have float datatype, 1 has int datatype and 1 has object datatype.
Feature Engineering
The feature engineering process involves identifying the relevant features from the available dataset and then creating new features that can improve the model’s predictive power.
This could include combining features, transforming variables, or selecting only the most important features for the model. By engineering the features, the model can make more accurate predictions, resulting in better performance and more valuable insights.
In this dataset, we will perform some feature engineering to combine or derive new features. For example, adding new columns such as day, month, and hour to the data frame by extracting the day component from the existing timestamp column.
# as the datatype of timestamp is object we need to convert it into datetime
bike_data["timestamp"] = pd.to_datetime(bike_data["timestamp"])
# deriving month feature
bike_data["month"] = bike_data["timestamp"].apply(lambda x:x.month)
# deriving day feature
bike_data["day"] = bike_data["timestamp"].apply(lambda x:x.day)
# deriving hour feature
bike_data["hour"] = bike_data["timestamp"].apply(lambda x:x.hour)
# removing timestamp feature as there is no use now
bike_data = bike_data.drop("timestamp", axis=1)
# checking dataframe
bike_data.head()
As weather_code and season are categorical variables so we need to handle them by transforming into numerical values using One Hot Encoding.
# One-hot encoding
## 1. encoding weather_code
dummies_w = pd.get_dummies(bike_data["weather_code"], prefix="weather")
bike_data = pd.concat([bike_data,dummies_w], axis=1)
bike_data = bike_data.drop("weather_code", axis=1)
## 2. encoding season
dummies_s = pd.get_dummies(bike_data["season"], prefix="season")
bike_data = pd.concat([bike_data,dummies_s], axis=1)
bike_data = bike_data.drop("season", axis=1)Now, let’s start to deep dive into analyzing data by examining a few key descriptive statistics. We can use the dataframe’s describe method to generate these for the numeric features as well as the cnt label column.
numeric_features = ['t1', 't2', 'hum', 'wind_speed','day','hour','month'] bike_data[numeric_features + ['cnt']].describe()

The above statistics provide information about the distribution of the data in the numeric fields, including the number of observations (731 records), mean, standard deviation, minimum and maximum values, and quartile values (25%, 50% – which is the median, and 75% of the data).
Based on these statistics, the mean number of daily bike share counts is approximately 1143, with a slight variance in the number of bike shares per day, as indicated by the difference in standard deviation.
To gain a clearer understanding of the distribution of bike share values, we can visualize the data using histograms and box plots. For this purpose, we will use Python’s matplotlib library to create these plots for the “cnt” column.
import pandas as pd
import matplotlib.pyplot as plt
# This ensures plots are displayed inline in the Jupyter notebook
%matplotlib inline
# Get the label column
label = bike_data['cnt']
# Create a figure for 2 subplots (2 rows, 1 column)
fig, ax = plt.subplots(2, 1, figsize = (9,12))
# Plot the histogram
ax[0].hist(label, bins=100)
ax[0].set_ylabel('Frequency')
# Add lines for the mean, median, and mode
ax[0].axvline(label.mean(), color='magenta', linestyle='dashed', linewidth=2)
ax[0].axvline(label.median(), color='cyan', linestyle='dashed', linewidth=2)
# Plot the boxplot
ax[1].boxplot(label, vert=False)
ax[1].set_xlabel('bike shares')
# Add a title to the Figure
fig.suptitle('Bike Share Distribution')
# Show the figure
fig.show()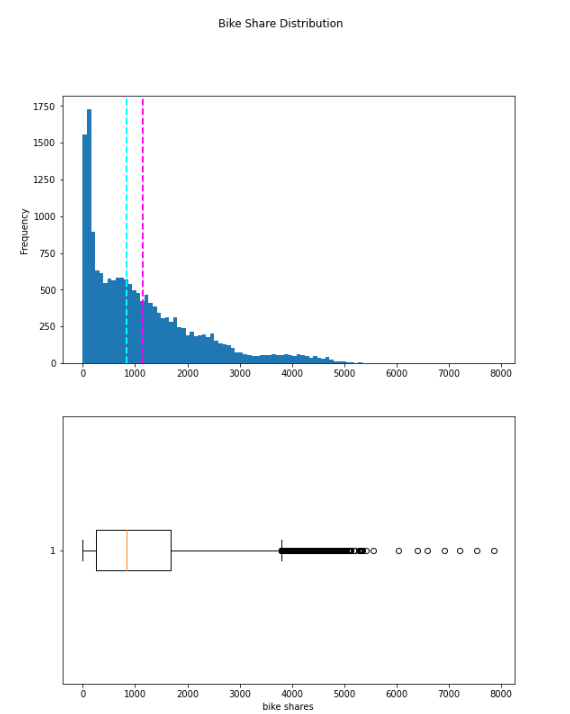
The plotted data displays the range of daily bike rentals, which spans from 0 to slightly over 5000. However, the mean (and median) number of daily rentals is closer to the lower end of this range, with the majority of the data being between 0 and approximately 1800 bike shares. The box plot depicts the few values above this range as small circles, indicating that they are outliers – that is, they are unusual values that fall outside the typical range of most of the data.
We can apply the same method of visual exploration to the other numeric features by creating histograms for each of them.
# Plot a histogram for each numeric feature
for col in numeric_features:
fig = plt.figure(figsize=(9, 6))
ax = fig.gca()
feature = bike_data[col]
feature.hist(bins=100, ax = ax)
ax.axvline(feature.mean(), color='magenta', linestyle='dashed', linewidth=2)
ax.axvline(feature.median(), color='cyan', linestyle='dashed', linewidth=2)
ax.set_title(col)
plt.show()
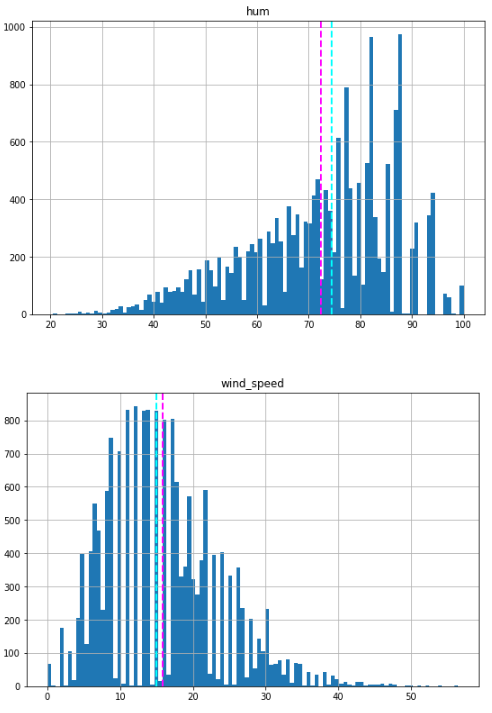

The numeric features displayed above appear to have a more normal distribution, with the mean and median located towards the middle of the range of values. However, in the case of humidity, the mean and median are towards the right side, coinciding with where the most commonly occurring values are.
Please note that the distributions are not truly normal in the statistical sense, which would result in a smooth, symmetrical “bell-curve” histogram with the mean and mode (the most common value) in the center. Nevertheless, they do suggest that most of the observations have a value somewhere near the middle.
In addition to creating histograms, we can also generate scatter plots that illustrate the intersection of feature and label values for the numeric features. Furthermore, we can calculate the correlation statistic to measure the apparent relationship between them.
for col in numeric_features:
fig = plt.figure(figsize=(9, 6))
ax = fig.gca()
feature = bike_data[col]
label = bike_data['cnt']
correlation = feature.corr(label)
plt.scatter(x=feature, y=label)
plt.xlabel(col)
plt.ylabel('Bike Shares')
ax.set_title('Bike Shares vs ' + col + '- correlation: ' + str(correlation))
plt.show()



Although not conclusive, upon closer examination of the scatter plots for t1 and t2, we can discern a faint diagonal trend suggesting that higher bike share counts tend to coincide with higher temperatures. A correlation value of just over 0.5 for both of these features supports this observation. Conversely, the plots for hum and windspeed display a slightly negative correlation, indicating that there are fewer bike rentals on days with high humidity or windspeed.
Moving forward, we can compare the categorical features to the label by creating box plots that display the distribution of share counts for each category.
# plot a bar plot for each categorical feature count
categorical_features = ['is_weekend','is_holiday','day','month','hour']
# plot a boxplot for the label by each categorical feature
for col in categorical_features:
fig = plt.figure(figsize=(9, 6))
ax = fig.gca()
bike_data.boxplot(column = 'cnt', by = col, ax = ax)
ax.set_title('Bike Shares by ' + col)
ax.set_ylabel("Bike Share Counts")
plt.show()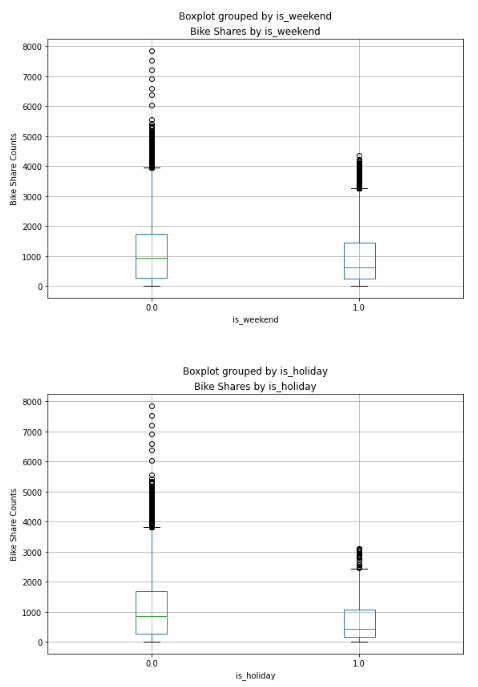


The plotted data reveals some variation in the relationship between certain category values and bike rentals. For instance, the distribution of bike shares is similar on weekends and holidays. Additionally, a clear trend indicates that there are different bike share distributions during daytime hours (10 AM to 3 PM) compared to evening and nighttime hours.
Train a Regression Model
Now that we have examined the data, our next step is to use it to train a regression model that employs the potentially predictive features we have identified to forecast the “cnt” label. To begin, we must segregate the features we want to utilize for training the model from the label that we aim to predict.
# Segregating Features and Target variable as X and y respectively
X = bike_data.drop("cnt", axis=1)
y = bike_data["cnt"]Upon segregating the dataset, we now possess two NumPy arrays: X, which comprises the features, and y, which comprises the labels.
Although we could train a model using all of the data, it’s customary in supervised learning to divide the data into two subsets: one (typically larger) subset to train the model and another smaller “hold-back” subset to validate the trained model. This approach allows us to assess the model’s performance by comparing the predicted labels to the known labels when it is used with the validation dataset. Randomly splitting the data is critical (as opposed to, say, taking the first 80% of the data for training and reserving the remainder for validation) to ensure that both subsets have a similar statistical distribution.
To split the data randomly, we will employ the train_test_split function found in the scikit-learn library. This library is among the most widely used machine learning packages for Python.
from sklearn.model_selection import train_test_split
# Split data 70%-30% into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=0)
print ('Training Set: %d rows\nTest Set: %d rows' % (X_train.shape[0], X_test.shape[0]))
Now we have the following four datasets:
- X_train: The feature values we’ll use to train the model
- y_train: The corresponding labels we’ll use to train the model
- X_test: The feature values we’ll use to validate the model
- y_test: The corresponding labels we’ll use to validate the model
At this point, we can train a model by applying a regression algorithm that can fit the training data. We will employ a linear regression algorithm, which is a common starting point for regression. This algorithm works by attempting to determine a linear relationship between the “X” values and the “y” label. Ultimately, the resulting model will be a function that outlines a line that intersects every conceivable combination of “X” and “y” values.
Feature Scaling
Scaling is a common technique utilized as part of the data preparation process for machine learning. The objective of scaling is to adjust the values of numeric columns in the dataset to a shared scale, without compromising the differences in the value ranges. We will employ the standard scaler for standardization.
Standardization is another scaling technique that centralizes the values around the mean with a unit standard deviation. This means that the attribute’s mean becomes zero, and the resulting distribution has a unit standard deviation.
from sklearn.preprocessing import StandardScaler scaler= StandardScaler() X_train[['t1', 't2', 'hum', 'wind_speed','month','day', 'hour']] = scaler.fit_transform(X_train[['t1', 't2', 'hum', 'wind_speed','month','day', 'hour']]) X_test[['t1', 't2', 'hum', 'wind_speed','month','day', 'hour']] = scaler.transform(X_test[['t1', 't2', 'hum', 'wind_speed','month','day', 'hour']]) # Train the model from sklearn.linear_model import LinearRegression # Fit a linear regression model on the training set model = LinearRegression().fit(X_train, y_train)
Evaluate Trained Model
Now that we have trained the model, we can use it to predict bike share counts for the features we retained in our validation dataset. We can then evaluate the model’s performance by comparing these predictions to the actual label values. This assessment will allow us to determine how effective the model is (or isn’t) in forecasting.
import numpy as np
predictions = model.predict(X_test)
np.set_printoptions(suppress=True)
print('Predicted labels: ', np.round(predictions)[:10])
print('Actual labels : ' ,y_test[:10])
import matplotlib.pyplot as plt
%matplotlib inline
plt.scatter(y_test, predictions)
plt.xlabel('Actual Labels')
plt.ylabel('Predicted Labels')
plt.title('Daily Bike Share Predictions')
# overlay the regression line
z = np.polyfit(y_test, predictions, 1)
p = np.poly1d(z)
plt.plot(y_test,p(y_test), color='magenta')
plt.show()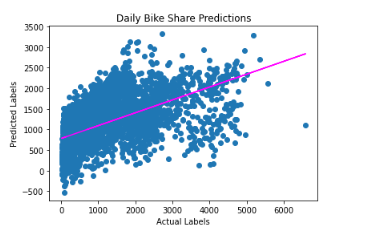
There is an apparent diagonal trend, and the points where the predicted and actual values intersect generally follow the trend line. However, there is a noticeable difference between the ideal function represented by the line and the results.
This variation represents the model’s residuals, which are the differences between the predicted label and the actual value of the validation label when the model applies the coefficients it learned during training to the validation data.
By assessing these residuals from the validation data, we can estimate the level of error that can be expected when the model is used with new data for which the label is unknown.
We can calculate several commonly used evaluation metrics to quantify the residuals. The three metrics we will focus on are:
Mean Square Error (MSE): This represents the mean of the squared differences between predicted and actual values. It is a relative metric where a smaller value indicates a better model fit.
Root Mean Square Error (RMSE): This represents the square root of the MSE. It is an absolute metric in the same unit as the label (in this case, number of rentals). A smaller value indicates a better model fit. In a simplistic sense, it represents the average number of rentals by which the predictions are incorrect.
Coefficient of Determination (usually referred to as R-squared or R2): This is a relative metric where a higher value represents a better model fit. This metric indicates how much of the variance between predicted and actual label values the model can explain.
Note: You can find out more about these and other metrics for evaluating regression models in the Scikit-Learn documentation
Let’s use Scikit-Learn to calculate these metrics for our model, based on the predictions it generated for the validation data.
from sklearn.metrics import mean_squared_error, r2_score
mse = mean_squared_error(y_test, predictions)
print("MSE:", mse)
rmse = np.sqrt(mse)
print("RMSE:", rmse)
r2 = r2_score(y_test, predictions)
print("R2:", r2)
So now we’ve quantified the ability of our model to predict the number of rentals. It definitely has some predictive power, but we can probably do better!
Try Another Linear Algorithm
Let’s try training our regression model by using a Lasso algorithm. We can do this by just changing the estimator in the training code.
from sklearn.linear_model import Lasso
# Fit a lasso model on the training set
model = Lasso().fit(X_train, y_train)
print (model, "\n")
# Evaluate the model using the test data
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print("MSE:", mse)
rmse = np.sqrt(mse)
print("RMSE:", rmse)
r2 = r2_score(y_test, predictions)
print("R2:", r2)
# Plot predicted vs actual
plt.scatter(y_test, predictions)
plt.xlabel('Actual Labels')
plt.ylabel('Predicted Labels')
plt.title('Daily Bike Share Counts')
# overlay the regression line
z = np.polyfit(y_test, predictions, 1)
p = np.poly1d(z)
plt.plot(y_test,p(y_test), color='magenta')
plt.show()
Try a Decision Tree Algorithm
Instead of utilizing a linear model, there exists a group of algorithms for machine learning that adopt a tree-based methodology. In this approach, the features in the dataset are scrutinized through a series of evaluations, with each evaluation resulting in a branch in a decision tree based on the feature value. At the end of each branch, there are leaf nodes with the predicted label value derived from the feature values.
To better comprehend this process, let’s use the bike rental data to train a Decision Tree regression model. After training the model, the code will display the model definition and a text-based illustration of the tree that it uses to forecast label values.
from sklearn.tree import DecisionTreeRegressor
# Train the model
model = DecisionTreeRegressor().fit(X_train, y_train)
# Evaluate the model using the test data
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print("MSE:", mse)
rmse = np.sqrt(mse)
print("RMSE:", rmse)
r2 = r2_score(y_test, predictions)
print("R2:", r2)
# Plot predicted vs actual
plt.scatter(y_test, predictions)
plt.xlabel('Actual Labels')
plt.ylabel('Predicted Labels')
plt.title('Daily Bike Share Predictions')
# overlay the regression line
z = np.polyfit(y_test, predictions, 1)
p = np.poly1d(z)
plt.plot(y_test,p(y_test), color='magenta')
plt.show()
As we can observe from the above results, our R2 score shoots up to 0.9169 from 0.319 which signifies our model has higher predictive power and that is evident from the plot.
Try an Ensemble Algorithm
Ensemble algorithms operate by integrating multiple base estimators to generate an optimal model, either by employing an aggregate function to a group of base models (referred to as “bagging”) or by constructing a series of models that enhance one another to enhance predictive performance (known as “boosting”).
Let’s take the Random Forest model as an instance, which uses an averaging function to multiple Decision Tree models to develop a superior overall model.
from sklearn.ensemble import RandomForestRegressor
# Train the model
model_rf = RandomForestRegressor().fit(X_train, y_train)
print (model_rf, "\n")
# Evaluate the model using the test data
predictions = model_rf.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print("MSE:", mse)
rmse = np.sqrt(mse)
print("RMSE:", rmse)
r2 = r2_score(y_test, predictions)
print("R2:", r2)
# Plot predicted vs actual
plt.scatter(y_test, predictions)
plt.xlabel('Actual Labels')
plt.ylabel('Predicted Labels')
plt.title('Daily Bike Share Predictions')
# overlay the regression line
z = np.polyfit(y_test, predictions, 1)
p = np.poly1d(z)
plt.plot(y_test,p(y_test), color='magenta')
plt.show()
So, random forest is more accurate than a decision tree having R2 score 0.954 and MSE, RMSE are also quite lower than the decision tree algorithm.
Conclusion
In conclusion, we have thoroughly examined the London bike-sharing dataset and performed extensive exploratory data analysis. We used various regression algorithms, including linear, tree-based, and ensemble models, to predict bike rental counts based on various features. After evaluating the results, we discovered that the Random Forest model outperformed the others with a higher R2 score and lower MSE and RMSE.
These findings suggest that Random Forest is a suitable algorithm for predicting bike rentals, and this study provides valuable insights into the factors that influence bike rental counts. These insights could potentially aid in making informed decisions regarding bike-sharing schemes in urban areas. Overall, this study highlights the power of machine learning algorithms in analyzing and predicting complex phenomena and their potential to inform real-world decision-making.