
Table of Contents
In the last lesson, we studied the bag of words representation which is a naive way of representing text as it relies solely on the frequencies of the words in a document. In this lesson, we will study, another smarter way of document representation i.e., TF-IDF. TF-IDF representation is the preferred method of document representation in practical scenarios.
The term TF stands for term frequency, and the term IDF stands for inverse document frequency.
The TF-IDF representation takes into account the importance of each word in a document. In the bag-of-words model, each word is assumed to be equally important, which is obviously a less accurate assumption.
The method to calculate the TF-IDF weights of a term in a document is given by the following formula:

Now, the TF-IDF score for any term in a document is the product of these two terms:
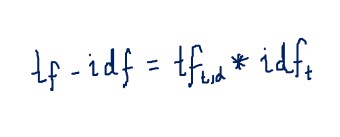
In the TF-IDF approach, higher weights are assigned to the frequently occurring terms in a document and are also rare among all documents. On the other hand, a low score is assigned to terms that are common across all documents.
Understanding TF-IDF with example
Let’s understand the working of TF-IDF with the example. Assume we have three sentences given below:
- Inflation has increased unemployment
- The company has increased its sales
- Fear increased his pulse
TF-IDF can be implemented in four steps for representing the above 3 sentences.
Step 1: Data Pre-processing
After lowercasing and removing stop words the sentences are transformed as below:

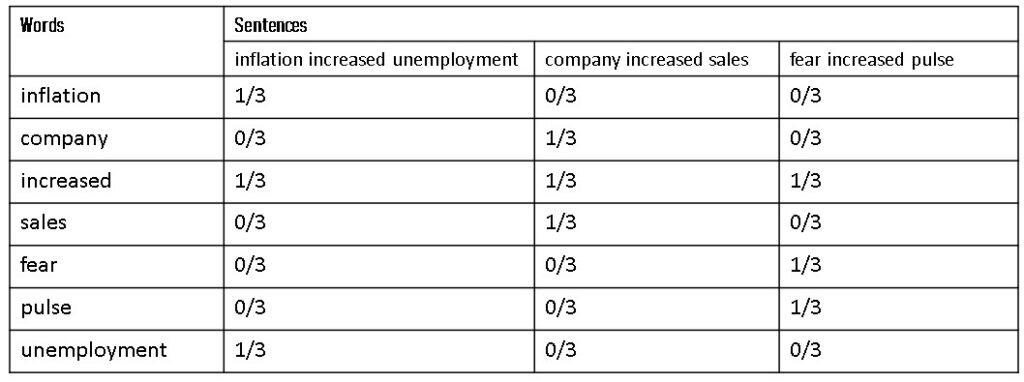
Step 2: Calculating Term Frequency
In this step, we have to calculate TF i.e., the Term Frequency of our given sentences.
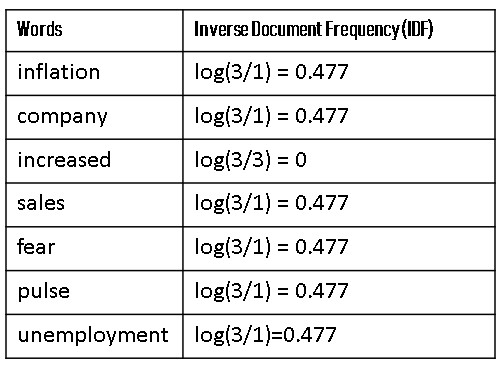
Step 3: Calculating Inverse Document Frequency
Now, next, we have to calculate the Inverse Document Frequency (IDF) of all the words in the sentences.
Step 4: Calculating Product of Term Frequency & Inverse Document Frequency
Now, the last step is to take the product of the term frequency of each of the words with their inverse document frequency. Now the table of TF-IDF will look like as below:

After simplifying the above table we will get the final TF-IDF matrix as follows:

From the above TF-IDF matrix, we can observe that in sentence 1 (inflation increased unemployment) the words “inflation” and “unemployment” got higher importance.
Similarly, in sentence 2 (company increased sales) the words “company” and “sales” got higher importance, and in sentence 3 (fear increased pulse) the words “fear” and “pulse” got higher importance.
The words that attained higher importance also have some form of semantic meaning in the sentence whereas the word “increased” doesn’t get much importance as it is frequently available across all the documents and has the same meaning across documents.
So, for building a TF-IDF model we have to give all the input features i.e., vocabulary along with the documents to the TF-IDF model and it will result in a TF-IDF matrix which will be used for training our machine learning model for document classification.
Next, we will see the implementation of TF-IDF in python.
TF-IDF implementation in Python
Let’s build the basic TF-IDF model using the above three sample sentences. For using the TF-IDF model we have to import it from the method sklearn.feature_extraction.text. The Python code for building the TF-IDF model is given below:
# load all necessary libraries
import pandas as pd
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
pd.set_option('max_colwidth', 100)
# taking sample sentences for building TF-IDF model
documents = ["Inflation has increased unemployment",
"The company has increased its sales",
"Fear increased his pulse"]
# defining preprocess function for lowercasing, tokenizing anf stop words removal
def preprocess(document):
'changes document to lower case and removes stopwords'
# change sentence to lower case
document = document.lower()
# tokenize into words
words = word_tokenize(document)
# remove stop words
words = [word for word in words if word not in stopwords.words("english")]
# join words to make sentence
document = " ".join(words)
return document
#applying preprocess function to the sample sentences
documents = [preprocess(document) for document in documents]
print(documents)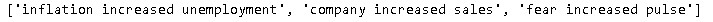
After cleaning the sample sentences we have to create a TF-IDF model using Tfidf vectorizer function.
vectorizer = TfidfVectorizer() tfidf_model = vectorizer.fit_transform(documents) print(tfidf_model)
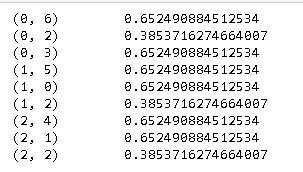
The above code returns the row number and column number of cells that have 1 as the value. Now, if we want to print it in the form of the sparse matrix we have to execute the below code.
# print the full sparse matrix print(tfidf_model.toarray())

Next, we will convert the above sparse matrix into a pandas dataframe and assign all the words of the documents as the columns of the dataframe.
pd.DataFrame(tfidf_model.toarray(), columns = vectorizer.get_feature_names())
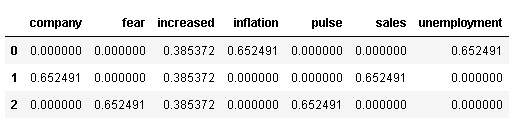
So, at last, we have built our TF-IDF model where the sample sentences are converted into matrix format with higher weights assigned to semantically important words in a document such as inflation and unemployment in sentence 1, company and sales in sentence 2, and fear and pulse in sentence 3 while frequent word across all the documents i.e., increased assigned with lower weights i.e., 0.385372
Conclusion
In this lesson, we have studied the basic concept of TF-IDF with detailed examples. Further, we have implemented the TF-IDF model in python with the same sample sentences and found that words that are unique to the document received higher importance in comparison to frequently occurring words across all the documents.
In the next lesson, we will implement a real-time project i.e., Financial Sentiment Analysis Using Machine Learning, and compare TF-IDF with the Bag of Words model in python so that we can better understand both the approaches in a practical scenario.
Proceed to Financial Sentiment Analysis Using Machine Learning Project