Table of Contents
In this article, we will discuss in detail VGG16, its architecture, reasons for its popularity in the computer vision domain, and what are its advantages over earlier CNN models.
What is VGG16?
VGG16 is a popular convolutional neural network (CNN) model that was developed by the Visual Geometry Group (VGG) at the University of Oxford in 2014.
This model achieved state-of-the-art performance on the ImageNet dataset, which is a widely used benchmark for image classification tasks.
VGG16 consists of 13 convolutional layers, followed by 3 fully-connected layers, and is a simple yet powerful model that has found widespread use in a variety of applications.
VGG16 was introduced in this paper. Our recommendation is to read this paper in detail to understand the VGG16 network in more detail.
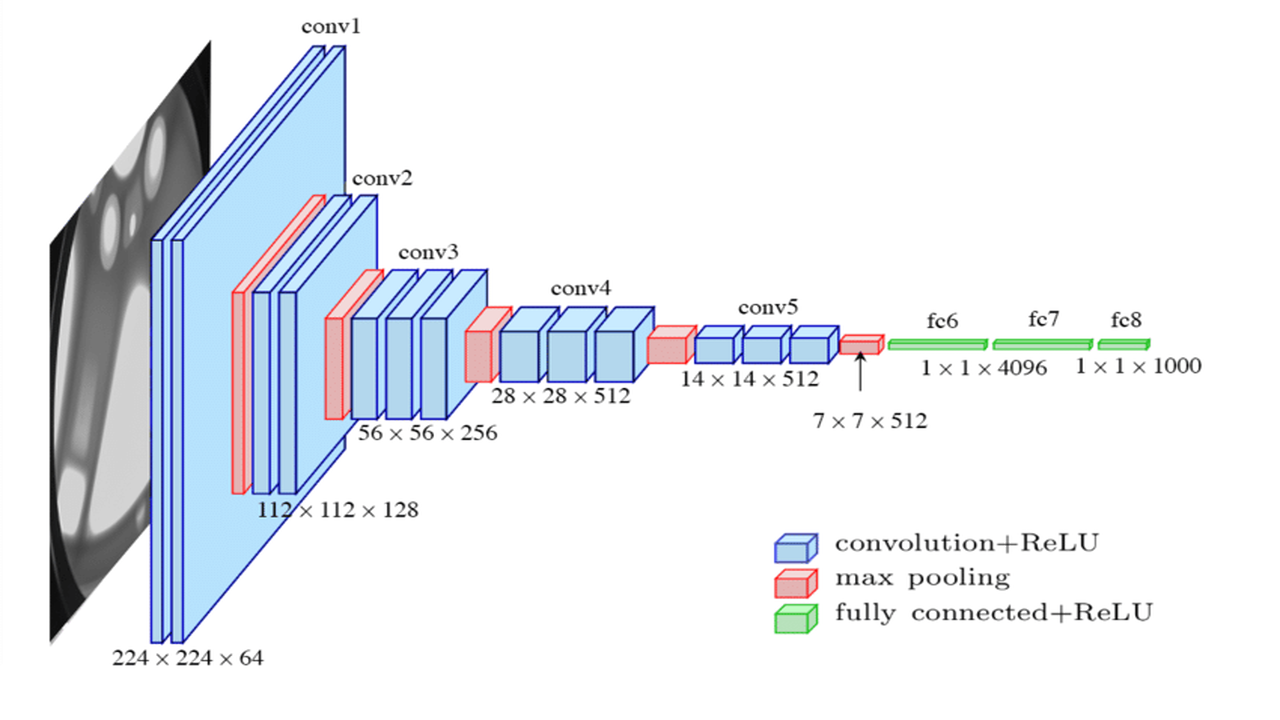
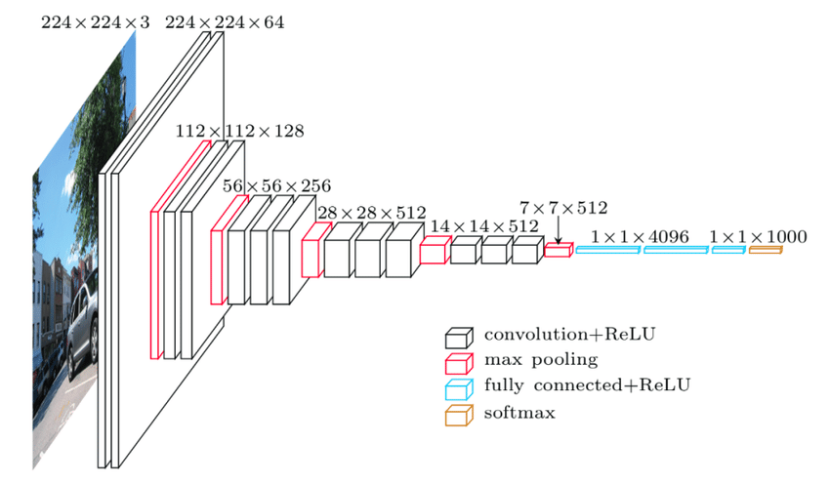
Architecture of VGG-16
The architecture of VGG16 is a convolutional neural network model that consists of 13 convolutional layers, followed by 3 fully-connected layers.
The input to the model is a 224×224 RGB image, which is passed through the convolutional layers. These layers extract features from the input image, and they are followed by max-pooling layers that reduce the spatial dimensionality of the feature maps.
Following the convolutional layers, the output is passed through fully-connected layers that predict the class of the input image.
The final layer of the model is a softmax layer, which outputs a probability distribution over the classes in the ImageNet dataset.
Why is VGG16 Popular?
VGG16 is popular for a number of reasons. First, it achieved state-of-the-art performance on the ImageNet dataset, which is a widely-used benchmark for image classification tasks.
Second, the architecture of the model is relatively simple, which makes it easy to understand and implement.
Finally, the model is pre-trained on the ImageNet dataset, which means that it can be fine-tuned for a wide range of image classification tasks with relatively little data.
Fine-Tuning VGG16
Fine-tuning VGG16 involves taking the pre-trained model and retraining it on a new dataset.
This is done by replacing the final layer of the model with a new layer that has the same number of output neurons as the number of classes in the new dataset.
The weights of the other layers are frozen, and only the weights of the new layer are updated during training.
Fine-tuning VGG16 can be a powerful technique for achieving high accuracy on image classification tasks, particularly when there is not a lot of training data available.
Advantage of VGG16 over AlexNet
Compared to the earlier CNN model AlexNet, VGG16 has several advantages.
The VGGNet succeeded AlexNet in the ImageNet challenge by reducing the error rate from about 17% to less than 8%.
Let’s discuss a number of reasons why VGG16 is better than AlexNet.
First, VGG16 has a deeper architecture with 13 convolutional layers, which allows it to learn more complex features and achieve better performance on image classification tasks.
Second, VGG16 uses smaller filter sizes (3×3) compared to AlexNet (11×11 and 5×5), it was able to use a higher number of non-linear activations with a reduced number of parameters.
Finally, the use of max-pooling layers in VGG16 helps to reduce the spatial dimensionality of the feature maps, which can improve generalization performance and reduce overfitting.
Conclusion
In conclusion, VGG16 is a powerful convolutional neural network model that is widely used for image classification tasks. Its architecture, with 13 convolutional layers and max-pooling layers, allows it to extract features from input images and achieve state-of-the-art performance on a variety of image recognition tasks.
Compared to AlexNet, VGG16’s deeper architecture, smaller filter sizes, and use of max-pooling layers make it a more efficient and effective model for image classification tasks.