Table of Contents
Till now we have learned two pre-processing techniques in text analytics i.e., tokenization and removal of stopwords. But still, we can’t use the text obtained after these two pre-processing steps for building a machine learning model.
In this lesson, we will study how to represent textual data in a format that is understandable to machine learning algorithms. For achieving the same, the most popular approach in practice is the Bag of Words (BoW) representation of the textual data.
Concept of Bag-of-Words (BoW)
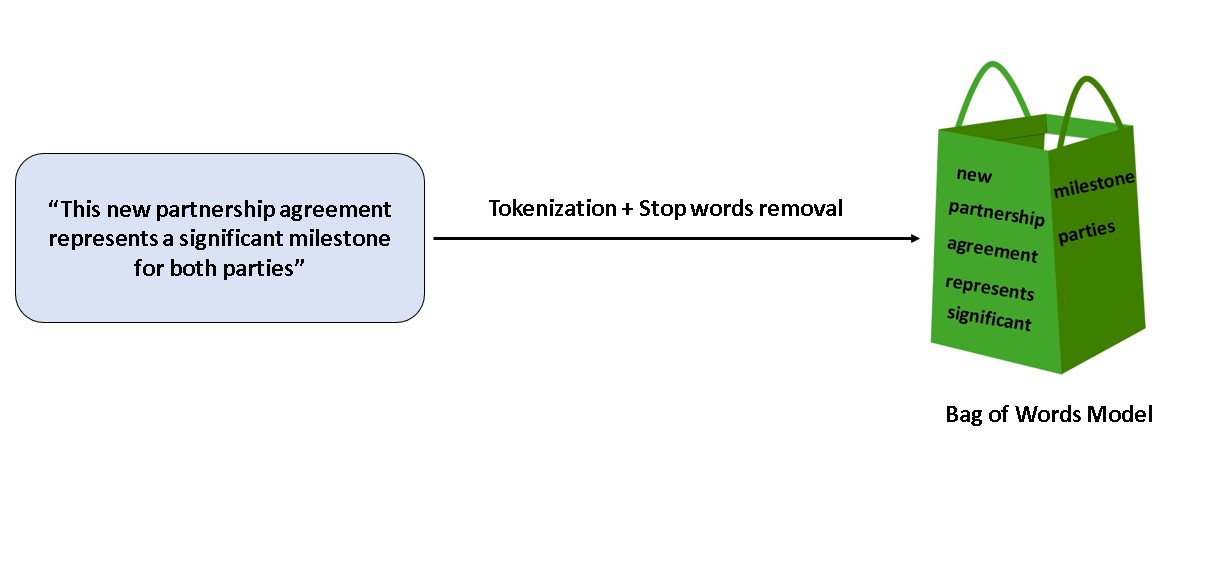
The core idea behind the Bag of Words (BoW) representation is that any given piece of text can be represented by a list of all unique words post stopwords removal. In the BoW approach order of words does not matter. For example, the below financial message can be represented in the form of a bag as shown in Fig 1.
“This new partnership agreement represents a significant milestone for both parties”

So, by creating the “bags” we can represent each of the messages in our training and test set. But the main question still remains how we can build financial messages sentiment analyzer from these “bags” representation?
Now, let’s say the bags, for most of the positive sentiment messages, contain words such as significant, increased, rose, appreciated, improved, etc., whereas negative sentiment bags contain words such as decreased, declined, loose, liquidated, etc.
So, whenever we get a new message, we have to look at its “bag-of-words” representation. Does the bag for this message resembles with the positive sentiment message or not ? Based on the answer to the above question, we can classify the message into appropriate sentiment.
Now, the next obvious question that comes to our mind is how the machine will create the bags of words automatically for sentiment classification.
So, the answer to this question is we have to represent all the bags in a matrix format, after which we can apply different machine learning algorithms like naive Bayes, logistic regression, support vector machines, etc., to do the final classification.
Bag of Words Example
Now, let’s understand the BoW approach by the following example. Let’s assume we have three documents as given below:
Document 1: Machine learning uses historical data to predict output values.
Document 2: It is seen as a part of artificial intelligence.
Document 3: Machine learning programs can perform tasks without being explicitly programmed to do so.
So, in the BoW approach, each document is represented on a separate row and each word of the vocabulary (post stopwords removal) has its own column. These vocabulary words are also known as features of the text.
| artificial | programs | data | output | machine | intelligence | perform | explicitly | historical | predict | seen | part | learning | tasks | values | programmed | without | uses | |
| D1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| D2 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| D3 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 |
The size of the above matrix is (3,18) where 3 denotes the number of rows i.e., the number of documents, and 18 represents the unique number of words over all the three documents excluding stopwords. These unique words represent columns also known as vocabulary and it is actually used as a feature of the text.
The above matrix was created by filling each cell with the frequency of each word in the documents Document 1, Document 2, and Document 3 represented by D1, D2, and D3 respectively.
The bag of words representation is also known as the bag of words model but it shouldn’t be confused with a machine learning model. A bag of words model is just the matrix representation of the frequency of words per document from actual raw textual data.
It is important to note that the values inside the cells can be filled in two ways:
- We can either fill the cell with the frequency of a word (values >=0)
- We can fill the cell with either 0, in case the word is not present or 1, in case the word is present also known as the binary bag of words model.
Out of the above two methods, the frequency approach is more commonly used in practice and the NLTK library in Python also fills the BoW model with word frequencies instead of binary 0 or 1 values.
Bag of Words implementation in python
Now we will implement the bag of words model in python. The code for the same is shared below.
# importing all necessary libraries
import pandas as pd
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import CountVectorizer
#setting max width to show all columns in dataframe
pd.set_option('max_colwidth', 100)
# building bag of words model on three sentences
documents = ["Machine learning uses historical data to predict output values.",
"It is seen as a part of artificial intelligence.",
"Machine learning programs can perform tasks without being explicitly programmed to do so."]
print(documents)
So, we will be using the above three sentences for building the bag of words model in python. Next, we have to perform certain pre-processing steps before building the model. Firstly, we have to lowercase all the words to bring every word in the universal casing else it will take “Machine” and “machine” as two separate words. Next, we need to tokenize the text and remove all the stopwords from the vocabulary. Lastly, we need to join back all the words into proper sentence format as shown in the below code.
def preprocess(document):
#changes document to lower case and removes stopwords'
# change sentence to lower case
document = document.lower()
# tokenize into words
words = word_tokenize(document)
# remove stop words
words = [word for word in words if word not in stopwords.words("english")]
# join back words to make sentence
document = " ".join(words)
return document
documents = [preprocess(document) for document in documents]
print(documents)

As we can see from the above output that now words in sentences are lowercased and there are no stopwords in those sentences.
Next, we will create bag-of-words model using count vectorizer function available in sklearn. This count vectorizer function will take these sentences as input and convert it into matrix representation where each cell will be filled by the frequency of particular vocab in that document.
vectorizer = CountVectorizer() bow_model = vectorizer.fit_transform(documents) print(bow_model) # returns the rows and column number of cells which have 1 as value
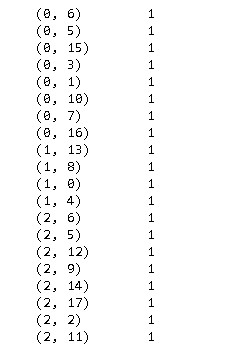
The above output is showing all the cells having 1 value. Next we will convert it into array format for creating a matrix representation.
# print the full sparse matrix print(bow_model.toarray())

Now, we can see the sentences are now converted into matrix format with the size (3,18) where 3 is number of documents (sentences in this case) and 18 are the number of unique vocabs.
Bag of Words for FinancialPhraseBank dataset
So, now, we will use FinacialPhraseBank dataset for creating bag of words model. For creating bag of words model for this dataset we need to follow below eight steps:
- Read the dataset
- Create the subset of 50 records
- Extract the text from the dataset
- Convert the extracted texts into list of texts
- Apply Pre process function to lowercase and stopwords removal
- Crating bag of words model using count vectorizer
- Apply fit and transform on list of processed texts obtained on step 5
- Convert the bag of words matrix to pandas dataframe by assigning all the vocabs as the column of the dataframe
# read the data
df = pd.read_csv("finbank_data.csv")
df.head()
The FinacialPhraseBank dataset has two columns text and label, where text consists of financial statements in the form of sentences whereas label denotes its sentiment positive, negative or neutral.
Let’s take a subset of data (first 50 rows only) and extract the texts from the dataframe.
After that we need to convert the texts messages into list of messages so that we can apply preprocess function (defined earlier in the article) for cleaning the same.
Post cleaning and removing the stopwords we will create bag of words model using count vectorizer funnction of sklearn.
#taking subset of data (first 50 rows only) df = df.iloc[0:50,:] # extract the messages from the dataframe texts = df.text # convert messages into list messages = [text for text in texts] # preprocess messages using the preprocess function messages = [preprocess(message) for message in messages] # creating bag of words model vectorizer = CountVectorizer() bow_model = vectorizer.fit_transform(messages)
So, after creating the bag of words model we will transform the matrxi into pandas dataframe so that we can set the column names as actual vocab words which are our features.
# creating dataframe from bag of words matrix representation df_bow = pd.DataFrame(bow_model.toarray(), columns = vectorizer.get_feature_names()) df_bow
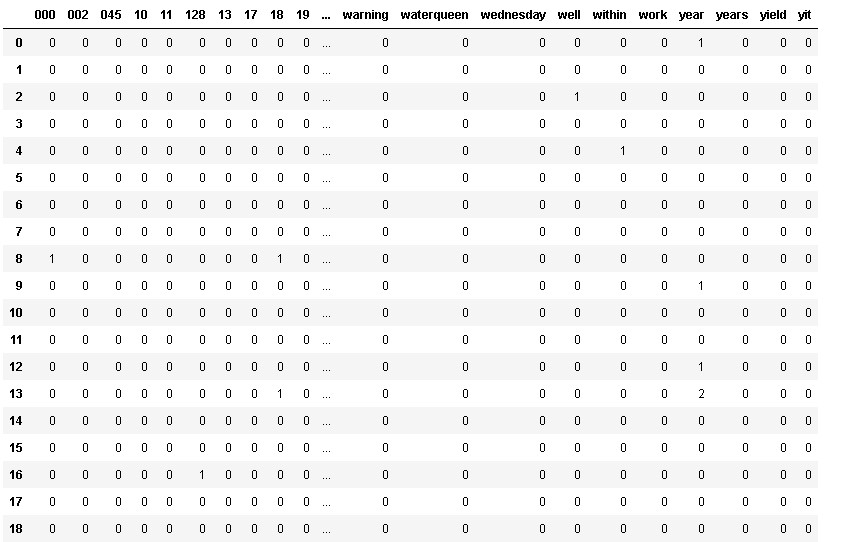
As we can see from above output that all the vocabs are designated as column names also known as features whereas number of documents i.e., 50 in our case are represented as rows.
Total 497 columns are generated out of all the documents.Further each cell is automatically filled with the frequency of that vocab in the particular document/record.
Next we will print all the vocabs to find any issues in that.
# printing all the features i.e., vocabs print(vectorizer.get_feature_names())

Issues in Bag of Words Model
As we can observe from above features, we get lots of redundant features after building the bag of words model. There were features such as ‘package’ and ‘packages’, ‘partner’ and ‘partnership’, ‘slight’ and ‘slightly’ and a lot of other duplicate features. They are not exactly duplicates but they’re redundant in the sense that they’re not giving us any extra information about the statement.
In fact, the words ‘improve’ and ‘improved’ are equivalent when our goal is to detect whether a staement is positive or negative.
Hence, keeping the two separate is actually going to affect the performance of the machine learning algorithms since it is redundant information.
Also, it will increase the number of features manifold due to which the classifier can face the issue of curse of dimensionality.
To get rid of the above issue, we are going to learn two other pre-processing techniques i.e., stemming and lemmatization in the next lesson.
Conclusion
So, in this lesson we have studied about the basic concept of bag of words model. Further we have implemented the bag of words model in python and found the issue of redundant/ duplicate features which can be resolved by using two other pre-processing techniques i.e., stemming and lemmatization.