
Table of Contents
In the last lesson, we have seen the issue of redundant vocabularies in the documents i.e., same meaning words having different variants resulted in separate features which increased the total number of features for building a machine learning model. In this lesson we will study two other preprocessing techniques in NLP i.e., stemming and lemmatization which will solve the problems of redundant vocabularies in the document.
Concept of Stemming
Stemming is the process of reducing the inflected forms of a word to its root form also known as the stem. For example, inflected forms of a word, say ‘warm’, warmer’, ‘warming’, and ‘warmed,’ are represented by a single token ‘warm’, because they all represent the same meaning.
Stemming is the rule-based technique for chopping off suffixes from the inflected forms of a word. The rules for chopping off the suffixes from the word are shown in the below image.
But we might think that the reduced forms or stems of the word ‘lies’ are not resembling the actual root words i.e., ‘li’.
Similarly in a sentence “the driver is racing in his car”, the words ‘driver’ and ‘racing’ will be converted to their root form by just chopping of the suffixes ‘er’ and ‘ing’. So, ‘driver’ will be converted to ‘driv’ and ‘racing’ will be converted to ‘rac’. The words ‘driv’ and ‘rac’ are not actual dictionary words.
However, we don’t have to worry about this because the stemmer will convert all the inflections of ‘driver’ and ‘racing’ to those root forms only. So, it will convert ‘drive’, ‘driving’, etc. to ‘driv’, and ‘race’, ‘racer’, etc. to ‘rac’. This gives us satisfactory results in most cases.
Types of Stemming
There are basically three types of stemmers available in the NLTK library:
- Porter Stemmer: In 1980, M.F. Porter invented this technique of steaming and that’s why it is named after his name Porter. This technique is very useful in the domain of information retrieval. But this technique works only on English words. For more details kindly visit here. The python code for implementing porter stemmer is given below:
from nltk.stem import PorterStemmer
porter = PorterStemmer()
words = ['generous','fairly','sings','generation']
for word in words:
print(word,"--->",porter.stem(word))

- Snowball Stemmer: This is an improved version of Porter stemming and also known as Porter2 stemming algorithm. Some of the rules of snowball stemming are shown in the below image. For more details visit here. The python code for implementing snowball stemmer is given below:
from nltk.stem import SnowballStemmer
snowball = SnowballStemmer(language='english')
words = ['generous','fairly','sings','generation']
for word in words:
print(word,"--->",snowball.stem(word))

3. Lancaster Stemmer: Lancaster stemmer is one of the most aggressive stemming algorithms. It sometimes over stems some of the words which results in non-linguistic or meaningless stem words. For more details visit here. The python code for implementing Lancaster stemmer is given below:
from nltk.stem import LancasterStemmer
lancaster = LancasterStemmer()
words = ['generous','fairly','sings','generation']
for word in words:
print(word,"--->",lancaster.stem(word))
Comparison of Porter vs Snowball vs Lancaster Stemmer
So, from the above output of all the stemmer algorithms, it is observed that the Lancaster stemmer is a very aggressive stemmer that over stems words such as “generous” and “generation” to “gen” whereas the snowball stemmer has done a pretty well job in stemming these words and most of its stems are proper English words only.

Lemmatization
Lemmatization is a more sophisticated technique than stemming in the sense that it doesn’t just chop off the suffix of a word. Instead, it takes an input word and searches for its root word by going recursively through all the variations of dictionary words. The base word, in this case, is called the lemma.
Words such as ‘feet’, ‘drove’, ‘arose’, ‘bought’, etc. can’t be reduced to their accurate base form using a lemmatizer. The most popular lemmatizer is the WordNet lemmatizer created by a team of researchers at the Princeton university. For more details, you can visit here.
Let’s try to implement a wordnet lemmatizer in python.
### import necessary libraries from nltk.stem import WordNetLemmatizer from nltk.tokenize import word_tokenize text = "Very orderly and methodical he looked, with a hand on each knee, and a loud watch ticking a sonorous sermon under his flapped newly bought waist-coat, as though it pitted its gravity and longevity against the levity and evanescence of the brisk fire." # tokenise text tokens = word_tokenize(text) wordnet_lemmatizer = WordNetLemmatizer() lemmatized = [wordnet_lemmatizer.lemmatize(token) for token in tokens] print(lemmatized)

Now, let’s compare lemmatization and stemming for the same text to get better visibility of both the techniques in practice.
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
stemmed = [stemmer.stem(token) for token in tokens]
# creating dataframe for comparing both stemmer and lemmatizer
import pandas as pd
df = pd.DataFrame(data={'token': tokens, 'stemmed': stemmed, 'lemmatized': lemmatized})
df = df[['token', 'stemmed', 'lemmatized']]
# printing only mismatched token
df[(df.token != df.stemmed) | (df.token != df.lemmatized)]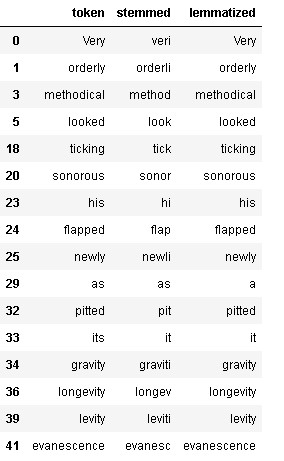
As we can observe from the above output, the lemmatizer is more accurate in terms of reducing inflected words as it outputs only proper English words whereas in most cases porter’s stemmer resulted in words that are improper or have no meaning in the English dictionary.
Comparison between Lemmatization and Stemming
Based on the above discussion, we may sometimes find ourselves confused about whether to use a stemmer or a lemmatizer in our application. The following points might help us in making the decision:
- A stemmer is a rule-based technique, and hence, it is much faster than the lemmatizer. However, a stemmer typically gives less accurate results than a lemmatizer.
- A lemmatizer is slower because of the dictionary lookup but gives better results than a stemmer. Now, it is important to know that for a lemmatizer to perform accurately, you need to provide the part-of-speech tag of the input word (noun, verb, adjective, etc.). But it is important to note that there are often cases when the POS tagger itself is quite inaccurate on our text and may worsen the performance of the lemmatizer as well. In short, we may consider a stemmer if we notice that POS tagging is inaccurate.
In the next lesson, we will study a new way of creating matrix representation from a text corpus of documents i.e., TF-IDF representation.