
Table of Contents
In this lesson, we will study stop words and why we should remove them from the text while building a text classification model using natural language processing and a machine learning approach.
Before jumping directly to the definition of stop words we should first understand their relevance and how we can figure them out in the real-time raw textual data.
As we all know that a text document is generally made up of characters, words, sentences, paragraphs, etc. If we want to get the intuition of text data then we can do basic statistical analysis by exploring word frequency distribution in the data.
Zipf’s law
According to Zipf’s law, if we plot the graph between the frequency of word distribution and the rank of a word in a large text corpus, then we will find that frequency of words will be inversely proportional to the rank of a word i.e., rank 1 is given to the most frequent word, 2 to the second most frequent word and so on.
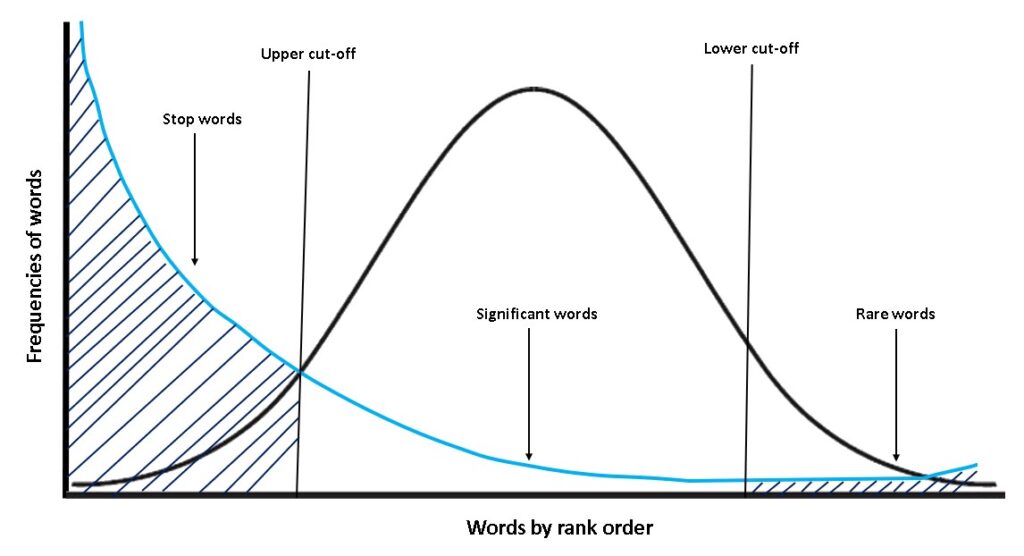
From the above graph, we can infer that there are generally three kinds of words in the document:
- Stop words, which are highly occurring words in the document such as ‘a’, ‘an’,’the’,’is’,’was’,’will’,’would’ etc.
- Significant words are those words that have a moderate frequency in the document and add actual meaning to the text. These words are more important than stop words.
- Rarely occurring words are those words that occur with very less frequency and have relatively lesser importance than significant words. Rarely occurring words may or may not be helpful in understanding the context of the text.
What are Stop words
So, therefore now we have a basic understanding of stop words that these words are highly occurring words in the document and to understand the document better we don’t need them because they don’t add any meaningful information.
Why we should remove stop words ?
Next comes a very important question: why we should remove stop words from the text. So, there are two main reasons for that:
- They provide no meaningful information, especially if we are building a text classification model. Therefore, we have to remove stopwords from our dataset.
- As the frequency of stop words are too high, removing them from the corpus results in much smaller data in terms of size. Reduced size results in faster computations on text data and the text classification model need to deal with a lesser number of features resulting in a robust model.
How to remove stop words in python ?
In the below code we will see the list of all stop words and how we can remove stop words from the text data.
# importing stop words from nltk corpus
from nltk.corpus import stopwords
# printing the list of all possible stop words in english language
print(stopwords.words('english'))
The above code results in printing all the possible stop words present in the English language using the NLTK library.
Let’s remove stop words from the following sample text.
“”” Natural language processing refers to the branch of computer science and more specifically, the branch of artificial intelligence or AI concerned with giving computers the ability to understand text and spoken words in much the same way human beings can understand.“””
sample_text = """Natural language processing refers to the branch of computer science and more specifically,
the branch of artificial intelligence or AI concerned with giving computers the ability to understand
text and spoken words in much the same way human beings can understand."""
# tokenize sample_text into words
sample_words = sample_text.split()
# identify all the stop words in sample text
found_stopwords = [word for word in sample_words if word in stopwords.words('english')]
print(found_stopwords)
Let’s remove these identified stop words from the sample text.
# removing stop words
no_stopwords = [word for word in sample_words if word not in stopwords.words('english')]
# joining back splitted words
sample_text = " ".join(no_stopwords)
print(sample_text)
From the above result, we can observe that all the stop words are removed successfully from the sample text. Now we can use this text as a feature for building the text classification model. But before that, we have to convert this sample text into a numeric format by encoding all the words in the sample text based on their frequency distribution in the document and that is possible using a technique called the Bag of Words model. So, in the next lesson, we will study the concept behind the Bag of Words model and how we can use it in building a text classifier.
Where we should not remove stop words ?
There are some applications in NLP such as Part of Speech (PoS) Tagging, Named Entity Recognition (NER), Parsing, etc., where we should not remove stop words besides we should preserve them as they actually provide grammatical information in those applications.
Proceed to Bag of Words model with complete implementation in Python
Frequently Asked Questions:
Why to remove stop words?
Stop words don’t provide any meaningful information and as their frequency are too high, removing them from the corpus results in much smaller data in terms of size and faster computations on text data.
What is stop word removal?
Stop words removal is the data pre-processing step in the natural language processing (NLP) pipeline in which we remove all the highly frequent words from the text as it doesn’t add any valuable information to understand the text better resulting in the NLP model dealing with less number of features.
How to remove stop words in python?
In order to remove stop words from the text in python, we have to use from nltk.corpus import stopwords and then create an object of stopwords by passing language as a parameter in stopwords.words(). Now this object is nothing but the list of all possible stop words in the language you mentioned. In the last step, we can include all the words excluding stop words in the text by using list comprehension and later join back all the words to form the text.