Table of Contents
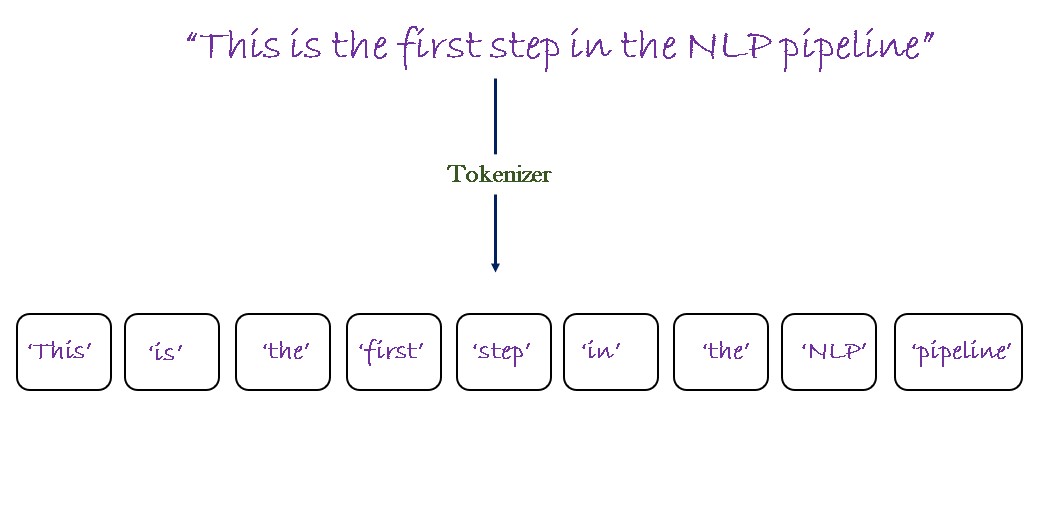
In this lesson, we will study the concept of tokenization. In natural language processing (NLP), tokenization is the process of breaking down the raw text into smaller chunks called tokens. Generally, these tokens can be characters, words, and sentences.
Why we need tokenization?
As we all know that machines can only understand numeric data so to make them understand the raw text we first need to break it down into words and later we usually encode them into a numeric format based on their frequency using a Bag of Words or based on their relevance using TF-IDF that we will study later in the course. So, in a nutshell, tokenization is an intermediate step for converting raw text into a machine-understandable format.
In the NLP pipeline, tokenization is the very first step of data processing which helps in further analysis of textual data by extracting useful features from it.
Types of Tokenizers in NLP
There are different types of tokenizers that are used based on different scenarios. For example, if we are building a phishing email detector using NLP we first need to tokenize mail content into words using a word tokenizer. Similarly if we want to analyze a paragraph sentence by sentence then we have to use a sentence tokenizer.
The NLTK library in python supports the following type of tokenizers:
- Word Tokenizer
- Sentence Tokenizer
- Tweet Tokenizer
- Regex Tokenizer
1. Word Tokenizer
In this type of tokenizer, we split the text into individual words. To achieve this in python, we can use split() method which split the text into words using whitespaces by default. This method of word tokenization is also known as Whitespace tokenization. But in practice, this method doesn’t always give good results as it fails to split contraction words such as “can’t”, “hasn’t”, “wouldn’t” etc. These issues will be resolved if we use NLTK based word tokenizer. It handles contraction words well and it also handles words such as “o’clock” which is not a contraction word.
document = '''At five o'clock in the morning I went to railway station near by my home.
I'll never go to that railway station again.
'''
print(document)
At five o'clock in the morning I went to railway station near by my home.
I'll never go to that railway station again.
Whitespace tokenization¶
print(document.split())
['At', 'five', "o'clock", 'in', 'the', 'morning', 'I', 'went', 'to', 'railway', 'station', 'near', 'by', 'my', 'home.', "I'll", 'never', 'go', 'to', 'that', 'railway', 'station', 'again.']
NLTK word tokenizer¶
from nltk.tokenize import word_tokenize
words = word_tokenize(document)
print(words)
['At', 'five', "o'clock", 'in', 'the', 'morning', 'I', 'went', 'to', 'railway', 'station', 'near', 'by', 'my', 'home', '.', 'I', "'ll", 'never', 'go', 'to', 'that', 'railway', 'station', 'again', '.']
As we can see from the above code the whitespace tokenizer is unable to identify the contraction word “I’ll” and also concatenated “.” with the words ‘home’ and ‘again’. On the other hand, NLTK’s word tokenizer not only breaks on whitespaces but also breaks contraction words such as I’ll into “I” and “‘ll” as well as it doesn’t break “o’clock” and treats it as a separate token.
2. Sentence Tokenizer
Tokenising based on a sentence requires us to split based on the period (‘.’). Let’s have a look at the NLTK sentence tokenizer in the below code.
document = '''At five o'clock in the morning I went to railway station near by my home.
I'll never go to that railway station again.
'''
print(document)
At five o'clock in the morning I went to railway station near by my home.
I'll never go to that railway station again.
NLTK sentence tokenizer¶
from nltk.tokenize import sent_tokenize
sentences = sent_tokenize(document)
print(sentences)
["At five o'clock in the morning I went to railway station near by my home.", "I'll never go to that railway station again."]
3. Tweet Tokenizer
A problem with word tokenizer is that it fails to tokenize emojis and other complex special characters such as words with hashtags. Emojis are common these days and people use them all the time.
msg="WIN with PRIMI to celebrate #NationalPizzaDay! RT this tweet, tell us what your fav PRIMI PIZZA is & stand to WIN a R250 voucher. This is gr8 <3 🥳🍕"
print(msg)
WIN with PRIMI to celebrate #NationalPizzaDay! RT this tweet, tell us what your fav PRIMI PIZZA is & stand to WIN a R250 voucher. This is gr8 <3 🥳🍕
from nltk.tokenize import word_tokenize
print(word_tokenize(msg))
['WIN', 'with', 'PRIMI', 'to', 'celebrate', '#', 'NationalPizzaDay', '!', 'RT', 'this', 'tweet', ',', 'tell', 'us', 'what', 'your', 'fav', 'PRIMI', 'PIZZA', 'is', '&', 'stand', 'to', 'WIN', 'a', 'R250', 'voucher', '.', 'This', 'is', 'gr8', '<', '3', '🥳🍕']
from nltk.tokenize import TweetTokenizer
tknzr = TweetTokenizer()
tknzr.tokenize(msg)
['WIN', 'with', 'PRIMI', 'to', 'celebrate', '#NationalPizzaDay', '!', 'RT', 'this', 'tweet', ',', 'tell', 'us', 'what', 'your', 'fav', 'PRIMI', 'PIZZA', 'is', '&', 'stand', 'to', 'WIN', 'a', 'R250', 'voucher', '.', 'This', 'is', 'gr8', '<3', '🥳', '🍕']
As we can see from the above code, the word tokenizer breaks the emoji ‘<3‘ into ‘<‘ and ‘3’ which is unacceptable in the domain of tweets language.
Emojis have their own significance in areas like sentiment analysis where a happy face and sad face can alone prove to be a really good predictor of sentiment. Similarly, the hashtags are broken into two tokens. A hashtag is used for searching for specific topics or photos on social media apps such as Instagram and Facebook. So there, you want to use the hashtag as is.
But tweet tokenizer handles all the emojis and the hashtags pretty well.
4. Regex Tokenizer
Regex tokenizer takes a regular expression and tokenizes and returns results based on the pattern specified in the regular expression.
Now, let’s say we want to tokenize the tweet message based on hashtags. Then let’s look at the below code to understand how to use the regex tokenizer.
from nltk.tokenize import regexp_tokenize
message = "WIN with PRIMI to celebrate #NationalPizzaDay! RT this tweet, tell us what your fav PRIMI PIZZA is & stand to WIN a R250 voucher. This is gr8 <3 🥳🍕"
pattern = "#[\w]+"
regexp_tokenize(message, pattern)
['#NationalPizzaDay']
As we can see from the above code the regex tokenizer successfully tokenizes the tweet based on the hashtag ‘NationalPizzaDay’
In the next lesson, we will learn what are Stopwords and why to remove them in the data pre-processing task in building an NLP pipeline.
Proceed to What are Stop words in NLP and Why we should remove them?
Frequently Asked Questions:
What is a sentence tokenizer?
The sentence tokenizer split paragraphs in raw text into individual sentences using period('.')
Why do we need tokenization?
As we all know that machines can only understand numeric data so to make them understand the raw text we first need to break it down into chunks or words so that we can encode them into a numeric format. So, in a nutshell, tokenization is an intermediate step for converting raw text into a machine-understandable format.
What is a regex tokenizer?
Regex tokenizer is available under the NLTK library which takes a regular expression and tokenizes the raw text based on the pattern specified in the regular expression.
What is Tweet tokenizer?
Tweet tokenizer is available under the NLTK library in python and it tokenizes raw tweet messages into individual tokens by handling emojis, hashtags, and @mentions as individual tokens which the word tokenizer fails to do.
What is tokenizer in NLTK?
NLTK supports four basic types of tokenizers under its module tokenize() i.e., word_tokenizer() for tokenizing text into words, sent_tokenizer() for tokenizing raw text into sentences, TweetTokenizer() for tokenizing tweet messages, and regexp_tokenize() for tokenizing raw text based on pattern specified in the regular expression.