
Table of Contents
Constituency parsing is an important concept in Natural Language Processing that involves analyzing the structure of a sentence grammatically by identifying the constituents or phrases in the sentence and their hierarchical relationships.
As we know that understanding natural language is a very complex task as we have to deal with the ambiguity of the natural language in order to properly understand the natural language.
Working of Constituency Parsing
For understanding natural language the key is to understand the grammatical pattern of the sentences involved. The first step in understanding grammar is to segregate a sentence into groups of words or tokens called constituents based on their grammatical role in the sentence.
Let’s understand this process with an example sentence:
“The lion ate the deer.”
Here, “The lion” represents a noun phrase, “ate” represents a verb phrase, and “the deer” is another noun phrase.
Let’s look at some of the more examples below:
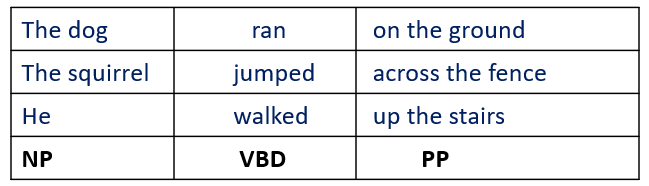
Context-Free Grammar (CFG)
The most common technique used in constituency parsing is Context-Free Grammar or CFG.
CFG works by organizing sentences into constituencies based on a set of grammar rules (or productions).
These rules specify how individual words in a sentence can be grouped to form constituents such as noun phrases, verb phrases, preposition phrases, etc.
A context-free grammar is defined as G =(N,Σ,R,S)
- N is a set of non-terminal symbols
- Σ is a set of terminal symbols
- R is a set of rules of the form where X →Y1Y2…Yn for n>=1, X ∈N,Yi ∈ (N∪Σ)
- S ∈N is a distinguished start symbol
From the above definition of CFG, we can say that CFG is a series of production rules.
Let’s understand the CFG using production rules in some English sentences.
The following production rule says that a noun phrase can be formed using either a determiner (DT) followed by a noun (N) or a noun phrase (NP) followed by a prepositional phrase (PP). :
NP -> DT N | NP PP
Some example phrases satisfying the above production rules are:
- The car.
- The bag over the bridge.
In the first sentence, The/DT (determiner) follows the noun phrase(NP) car/NP as per the first rule:
NP -> DT N.
In the second sentence, The bag is a noun phrase that follows the preposition phrase (over the bridge) as per the second rule:
NP -> NP PP
Therefore, in order to parse the sentences into different constituents we can use grammatical rules as shown in the above example using CFG.
In general, any production rule can be written as A -> B C, where A is a non-terminal symbol (NP, VP, N, etc.) and B and C are either non-terminals or terminal symbols
Python Implementation of Constituency Parsing
Python provides various tools and libraries for constituency parsing, including the Natural Language Toolkit (NLTK), Stanford Parser, and spaCy. NLTK is a popular Python library for NLP, which includes several functions for constituency parsing.
In this demo, we have used ChartParser from NLTK which is based on the concept of dynamic programming.
import nltk
sentence = "present all final results in a Word_Document"
tokens = nltk.word_tokenize(sentence)
your_grammar = nltk.CFG.fromstring("""
S -> V NP
V -> 'describe' | 'present'
NP -> PRP N | DT N PP | DT N | ADJ N PP | DT NP
PRP -> 'your'
N -> 'work' | 'step' | 'results' | 'Word_Document'
PP -> P NP
P -> 'of' | 'in'
DT -> 'every' | 'a' | 'all'
ADJ -> 'final'
""")
parser = nltk.ChartParser(your_grammar)
print (list(parser.parse(tokens)))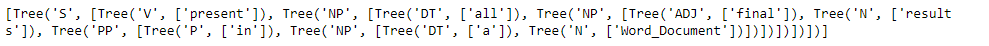
In this code, we first tokenize the input sentence using the word_tokenize function from NLTK. We then define context-free grammar using the CFG.fromstring function, which specifies the rules for constructing phrases in the sentence. Finally, we create a chart parser using the ChartParser class and parse the sentence using the parse function.
Advantages and Disadvantages of Constituency Parsing
Constituency parsing has several advantages in NLP. First, it allows us to analyze the grammatical structure of a sentence, which is essential for many NLP tasks such as information retrieval and machine translation.
Second, it provides a hierarchical representation of the sentence that can be used for further analysis, such as identifying the sentiment of the sentence or extracting key phrases.
However, constituency parsing also has some disadvantages. First, it can be computationally expensive, especially for long sentences or large datasets.
Second, it may not always produce accurate parse trees, especially for ambiguous or complex sentences.
Finally, constituency parsing may not be suitable for languages with non-linear or free word order, such as some Asian languages.
Application of Constituency Parsing
Constituency parsing has various applications in Natural Language Processing (NLP). Here are a few examples:
- Machine Translation: Constituency parsing can be used to analyze the grammatical structure of the source language sentence and generate a parse tree. This parse tree can then be used to identify key phrases and their relationships, which can aid in the translation process.
- Information Retrieval: Constituency parsing can be used to extract important information from text, such as named entities and relationships between them. This information can be used to improve search results and document classification.
- Question Answering: Constituency parsing can be used to identify the syntactic structure of a question and the corresponding answer, which can aid in answering questions accurately.
- Text Summarization: Constituency parsing can be used to identify the most important phrases and their relationships in a text, which can be used to generate a summary of the text.
- Sentiment Analysis: Constituency parsing can be used to identify the sentiment of a sentence by analyzing the grammatical structure of the sentence and identifying the key phrases and their relationships.
- Grammar Checking: Constituency parsing can be used to check the grammar of a sentence by analyzing the syntactic structure of the sentence and identifying any errors or inconsistencies.
Overall, constituency parsing is a versatile tool that can be applied to a wide range of NLP tasks to improve their accuracy and effectiveness.
FAQs
Q1. What is the difference between constituency parsing and dependency parsing?
Ans1. Constituency parsing involves analyzing the grammatical structure of a sentence by identifying the constituents or phrases in the sentence and their hierarchical relationships. In contrast, dependency parsing involves identifying the dependencies or relationships between words in the sentence.
Q2. What are the applications of constituency parsing in Natural Language Processing?
Ans2. Constituency parsing is used in many NLP applications such as sentiment analysis, machine translation, and information retrieval.
Q3. Can constituency parsing be used for non-English languages?
Ans3. Yes, constituency parsing can be used for non-English languages, although it may require language-specific models and training data.
Q4. What are the limitations of constituency parsing?
Ans4. Constituency parsing can be computationally expensive, may not always produce accurate parse trees, and may not be suitable for languages with non-linear or free word order.
Q5. How can constituency parsing be improved in the future?
Ans5. Constituency parsing can be improved by using more sophisticated machine learning algorithms, such as deep learning models, and by incorporating additional linguistic features and context information. Improvements in constituency parsing can also benefit from the availability of larger and more diverse training datasets, as well as more efficient and scalable parsing algorithms.