
Table of Contents
In this article, we will discuss the case study of detecting malicious URLs using lexical features with a boosted tree-based machine learning approach.
In the recent past, we have witnessed a significant increase in cybersecurity attacks such as ransomware, phishing, injection of malware, etc. on different websites all over the world. As a result of this, various financial institutions, e-commerce companies, and individuals incurred huge financial losses.
In such type of scenario containing a cyber security attack is a major challenge for cyber security professionals as different types of new attacks are coming day by day.
Hackers create 300,000 new pieces of malware daily.
Source: McAfee
On average 30,000 new websites are hacked every day.
Source: Forbes
The above quotes determine how rapidly these malicious websites spread all over the world on a daily basis.
Before moving towards the discussion of applying machine learning for detecting malicious URLs, first, try to understand what is URL? and what makes it malicious?
What is URL?
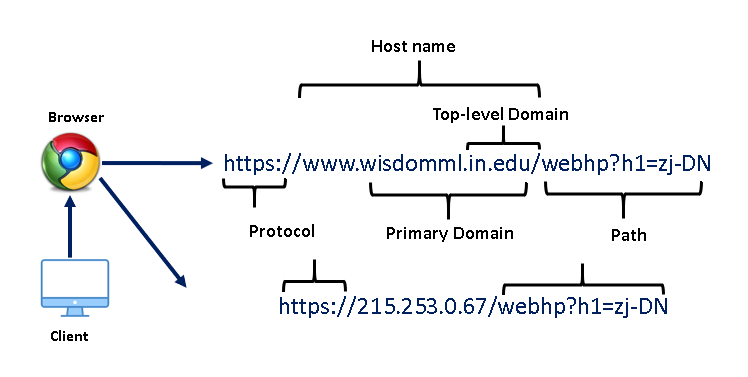
The Uniform Resource Locator (URL) is the well-defined structured format unique address for accessing websites over World Wide Web (WWW).
Generally, there are three basic components that make up a legitimate URL
i.) Protocol: It is basically an identifier that determines what protocol to use e.g., HTTP, HTTPS, etc.
ii) Hostname: Also known as the resource name. It contains the IP address or the domain name where the actual resource is located.
iii) Path: It specifies the actual path where the resource is located
As per the figure, wisdomml.in.edu is the domain name. The top-level domain is another component of the domain name that tells the nature of the website i.e, commercial (.com), educational (.edu), organization (.edu), etc.
What is Malicious URL?
Modified or compromised URLs employed for cyber attacks are known as malicious URLs.
A malicious URL or website generally contains different types of trojans, malware, unsolicited content in the form of phishing, drive-by-download, spams.
The main objective of the malicious website is to fraud or steal the personal or financial details of unsuspecting users. Due to the ongoing COVID-19 pandemic the incidents of cybercrime increased manifold. According to Symantec Internet Security Threat Report (ISTR) 2019, malicious URLs are a highly used technique in cyber crimes.
In this article, we address the detection of malicious URLs as a multi-class classification problem by classifying the raw URLs into different class types such as benign or safe URLs, phishing URLs, malware URLs, or defacement URLs.
Problem statement
In this case study, we address the detection of malicious URLs as a multi-class classification problem. In this case study, we classify the raw URLs into different class types such as benign or safe URLs, phishing URLs, malware URLs, or defacement URLs.
Project flow
As we know machine learning algorithms only support numeric inputs so we will create lexical numeric features from input URLs. So the input to machine learning algorithms will be the numeric lexical features rather than actual raw URLs. If you don’t know about lexical features you can refer to the discussion about a lexical feature in StackOverflow.
So, in this case study, we will be using three well-known machine learning ensemble classifiers namely Random Forest, Light GBM, and XGBoost.
Later, we will also compare their performance and plot average feature importance plot to understand which features are important in predicting malicious URLs.
Dataset description
In this case study, we will be using a Malicious URLs dataset of 6,51,191 URLs, out of which 4,28,103 benign or safe URLs, 96,457 defacement URLs, 94,111 phishing URLs, and 32,520 malware URLs.
Now, let’s discuss different types of URLs in our dataset i.e., Benign, Malware, Phishing, and Defacement URLs.
- Benign URLs: These are safe to browse URLs. Some of the examples of benign URLs are as follows:
- mp3raid.com/music/krizz_kaliko.html
- infinitysw.com
- google.co.in
- myspace.com
- Malware URLs: These type of URLs inject malware into the victim’s system once he/she visit such URLs. Some of the examples of malware URLs are as follows:
- proplast.co.nz
- http://103.112.226.142:36308/Mozi.m
- microencapsulation.readmyweather.com
- xo3fhvm5lcvzy92q.download
- Defacement URLs: Defacement URLs are generally created by hackers with the intention of breaking into a web server and replacing the hosted website with one of their own, using techniques such as code injection, cross-site scripting, etc. Common targets of defacement URLs are religious websites, government websites, bank websites, and corporate websites. Some of the examples of defacement URLs are as follows:
- http://www.vnic.co/khach-hang.html
- http://www.raci.it/component/user/reset.html
- http://www.approvi.com.br/ck.htm
- http://www.juventudelirica.com.br/index.html
- Phishing URLs: By creating phishing URLs, hackers try to steal sensitive personal or financial information such as login credentials, credit card numbers, internet banking details, etc. Some of the examples of phishing URLs are shown below:
- roverslands.net
- corporacionrossenditotours.com
- http://drive-google-com.fanalav.com/6a7ec96d6a
- citiprepaid-salarysea-at.tk
Next, we will plot the word cloud of different types of URLs.
Wordcloud of URLs
The word cloud helps in understanding the pattern of words/tokens in particular target labels.
It is one of the most appealing techniques of natural language processing for understanding the pattern of word distribution.
As we can see in the below figure word cloud of benign URLs is pretty obvious having frequent tokens such as html, com, org, wiki etc. Phishing URLs have frequent tokens as tools, ietf, www, index, battle, net whereas html, org, html are higher frequency tokens as these URLs try to mimick original URLs for deceiving the users.
The word cloud of malware URLs has higher frequency tokens of exe, E7, BB, MOZI. These tokens are also obvious as malware URLs try to install trojans in the form of executable files over the users’ system once the user visits those URLs.
The defacement URLs’ intention is to modify the original website’s code and this is the reason that tokens in its word cloud are more common development terms such as index, php, itemid, https, option, etc.

So, from the above word clouds, most of the tokens distribution in different types of URLs is now crystal clear.
Importing Libraries
In this step, we will import all the necessary python libraries which will be used in this project.
import pandas as pd import itertools from sklearn.metrics import classification_report,confusion_matrix, accuracy_score from sklearn.model_selection import train_test_split import pandas as pd import numpy as np import matplotlib.pyplot as plt import xgboost as xgb from lightgbm import LGBMClassifier import os import seaborn as sns from wordcloud import WordCloud
Next, we will load the dataset and will check sample records in the dataset to get an understanding of the data.
Loading dataset
In this step, we will import the dataset using the pandas library and check the sample entries in the dataset.
df=pd.read_csv('malicious_phish.csv')
print(df.shape)
df.head()
So from the above output, we can observe that the dataset has 6,51,191 records with two columns url containing the raw URLs and type which is the target variable.
Next, we will move towards the feature engineering part in which we will create lexical features from raw URLs.
Feature engineering
In this step, we will extract the following lexical features from raw URLs, as these features will be used as the input features for training the machine learning model. The following features are created as follows:
- having_ip_address: Generally cyber attackers use an IP address in place of the domain name to hide the identity of the website. this feature will check whether the URL has IP address or not.
- abnormal_url: This feature can be extracted from the WHOIS database. For a legitimate website, identity is typically part of its URL.
- google_index: In this feature, we check whether the URL is indexed in google search console or not.
- Count. : The phishing or malware websites generally use more than two sub-domains in the URL. Each domain is separated by dot (.). If any URL contains more than three dots(.), then it increases the probability of a malicious site.
- Count-www: Generally most of the safe websites have one www in its URL. This feature helps in detecting malicious websites if the URL has no or more than one www in its URL.
- count@: The presence of the “@” symbol in the URL ignores everything previous to it.
- Count_dir: The presence of multiple directories in the URL generally indicates suspicious websites.
- Count_embed_domain: The number of the embedded domains can be helpful in detecting malicious URLs. It can be done by checking the occurrence of “//” in the URL.
- Suspicious words in URL: Malicious URLs generally contain suspicious words in the URL such as PayPal, login, sign in, bank, account, update, bonus, service, ebayisapi, token, etc. We have found the presence of such frequently occurring suspicious words in the URL as a binary variable i.e., whether such words present in the URL or not.
- Short_url: This feature is created to identify whether the URL uses URL shortening services like bit. \ly, goo.gl, go2l.ink, etc.
- Count_https: Generally malicious URLs do not use HTTPS protocols as it generally requires user credentials and ensures that the website is safe for transactions. So, the presence or absence of HTTPS protocol in the URL is an important feature.
- Count_http: Most of the time, phishing or malicious websites have more than one HTTP in their URL whereas safe sites have only one HTTP.
- Count%: As we know URLs cannot contain spaces. URL encoding normally replaces spaces with symbol (%). Safe sites generally contain less number of spaces whereas malicious websites generally contain more spaces in their URL hence more number of %.
- Count?: The presence of symbol (?) in URL denotes a query string that contains the data to be passed to the server. More number of ? in URL definitely indicates suspicious URL.
- Count-: Phishers or cybercriminals generally add dashes(-) in prefix or suffix of the brand name so that it looks genuine URL. For example. www.flipkart-india.com.
- Count=: Presence of equal to (=) in URL indicates passing of variable values from one form page t another. It is considered as riskier in URL as anyone can change the values to modify the page.
- url_length: Attackers generally use long URLs to hide the domain name. We found the average length of a safe URL is 74.
- hostname_length: The length of the hostname is also an important feature for detecting malicious URLs.
- First directory length: This feature helps in determining the length of the first directory in the URL. So looking for the first ‘/’ and counting the length of the URL up to this point helps in finding the first directory length of the URL. For accessing directory level information we need to install python library TLD. You can check this link for installing TLD.
- Length of top-level domains: A top-level domain (TLD) is one of the domains at the highest level in the hierarchical Domain Name System of the Internet. For example, in the domain name www.example.com, the top-level domain is com. So, the length of TLD is also important in identifying malicious URLs. As most of the URLs have .com extension. TLDs in the range from 2 to 3 generally indicate safe URLs.
- Count_digits: The presence of digits in URL generally indicate suspicious URLs. Safe URLs generally do not have digits so counting the number of digits in URL is an important feature for detecting malicious URLs.
- Count_letters: The number of letters in the URL also plays a significant role in identifying malicious URLs. As attackers try to increase the length of the URL to hide the domain name and this is generally done by increasing the number of letters and digits in the URL.
The code for creating above mentioned features is shared below.
import re
#Use of IP or not in domain
def having_ip_address(url):
match = re.search(
'(([01]?\\d\\d?|2[0-4]\\d|25[0-5])\\.([01]?\\d\\d?|2[0-4]\\d|25[0-5])\\.([01]?\\d\\d?|2[0-4]\\d|25[0-5])\\.'
'([01]?\\d\\d?|2[0-4]\\d|25[0-5])\\/)|' # IPv4
'((0x[0-9a-fA-F]{1,2})\\.(0x[0-9a-fA-F]{1,2})\\.(0x[0-9a-fA-F]{1,2})\\.(0x[0-9a-fA-F]{1,2})\\/)' # IPv4 in hexadecimal
'(?:[a-fA-F0-9]{1,4}:){7}[a-fA-F0-9]{1,4}', url) # Ipv6
if match:
# print match.group()
return 1
else:
# print 'No matching pattern found'
return 0
df['use_of_ip'] = df['url'].apply(lambda i: having_ip_address(i))
from urllib.parse import urlparse
def abnormal_url(url):
hostname = urlparse(url).hostname
hostname = str(hostname)
match = re.search(hostname, url)
if match:
# print match.group()
return 1
else:
# print 'No matching pattern found'
return 0
df['abnormal_url'] = df['url'].apply(lambda i: abnormal_url(i))
#pip install googlesearch-python
from googlesearch import search
def google_index(url):
site = search(url, 5)
return 1 if site else 0
df['google_index'] = df['url'].apply(lambda i: google_index(i))
def count_dot(url):
count_dot = url.count('.')
return count_dot
df['count.'] = df['url'].apply(lambda i: count_dot(i))
def count_www(url):
url.count('www')
return url.count('www')
df['count-www'] = df['url'].apply(lambda i: count_www(i))
def count_atrate(url):
return url.count('@')
df['count@'] = df['url'].apply(lambda i: count_atrate(i))
def no_of_dir(url):
urldir = urlparse(url).path
return urldir.count('/')
df['count_dir'] = df['url'].apply(lambda i: no_of_dir(i))
def no_of_embed(url):
urldir = urlparse(url).path
return urldir.count('//')
df['count_embed_domian'] = df['url'].apply(lambda i: no_of_embed(i))
def shortening_service(url):
match = re.search('bit\.ly|goo\.gl|shorte\.st|go2l\.ink|x\.co|ow\.ly|t\.co|tinyurl|tr\.im|is\.gd|cli\.gs|'
'yfrog\.com|migre\.me|ff\.im|tiny\.cc|url4\.eu|twit\.ac|su\.pr|twurl\.nl|snipurl\.com|'
'short\.to|BudURL\.com|ping\.fm|post\.ly|Just\.as|bkite\.com|snipr\.com|fic\.kr|loopt\.us|'
'doiop\.com|short\.ie|kl\.am|wp\.me|rubyurl\.com|om\.ly|to\.ly|bit\.do|t\.co|lnkd\.in|'
'db\.tt|qr\.ae|adf\.ly|goo\.gl|bitly\.com|cur\.lv|tinyurl\.com|ow\.ly|bit\.ly|ity\.im|'
'q\.gs|is\.gd|po\.st|bc\.vc|twitthis\.com|u\.to|j\.mp|buzurl\.com|cutt\.us|u\.bb|yourls\.org|'
'x\.co|prettylinkpro\.com|scrnch\.me|filoops\.info|vzturl\.com|qr\.net|1url\.com|tweez\.me|v\.gd|'
'tr\.im|link\.zip\.net',
url)
if match:
return 1
else:
return 0
df['short_url'] = df['url'].apply(lambda i: shortening_service(i))
def count_https(url):
return url.count('https')
df['count-https'] = df['url'].apply(lambda i : count_https(i))
def count_http(url):
return url.count('http')
df['count-http'] = df['url'].apply(lambda i : count_http(i))
def count_per(url):
return url.count('%')
df['count%'] = df['url'].apply(lambda i : count_per(i))
def count_ques(url):
return url.count('?')
df['count?'] = df['url'].apply(lambda i: count_ques(i))
def count_hyphen(url):
return url.count('-')
df['count-'] = df['url'].apply(lambda i: count_hyphen(i))
def count_equal(url):
return url.count('=')
df['count='] = df['url'].apply(lambda i: count_equal(i))
def url_length(url):
return len(str(url))
#Length of URL
df['url_length'] = df['url'].apply(lambda i: url_length(i))
#Hostname Length
def hostname_length(url):
return len(urlparse(url).netloc)
df['hostname_length'] = df['url'].apply(lambda i: hostname_length(i))
df.head()
def suspicious_words(url):
match = re.search('PayPal|login|signin|bank|account|update|free|lucky|service|bonus|ebayisapi|webscr',
url)
if match:
return 1
else:
return 0
df['sus_url'] = df['url'].apply(lambda i: suspicious_words(i))
def digit_count(url):
digits = 0
for i in url:
if i.isnumeric():
digits = digits + 1
return digits
df['count-digits']= df['url'].apply(lambda i: digit_count(i))
def letter_count(url):
letters = 0
for i in url:
if i.isalpha():
letters = letters + 1
return letters
df['count-letters']= df['url'].apply(lambda i: letter_count(i))
# pip install tld
from urllib.parse import urlparse
from tld import get_tld
import os.path
#First Directory Length
def fd_length(url):
urlpath= urlparse(url).path
try:
return len(urlpath.split('/')[1])
except:
return 0
df['fd_length'] = df['url'].apply(lambda i: fd_length(i))
#Length of Top Level Domain
df['tld'] = df['url'].apply(lambda i: get_tld(i,fail_silently=True))
def tld_length(tld):
try:
return len(tld)
except:
return -1
df['tld_length'] = df['tld'].apply(lambda i: tld_length(i))So, now after creating the above 22 features, the dataset looks like the below.

Now, in the next step, we drop the irrelevant columns i.e., URL,google_index, and tld.
The reason for dropping the URL column is that we have already extracted relevant features from it that can be used as input in machine learning algorithms.
The tld column is dropped because it is the indirect textual column as for finding the length of the top-level domain we have created tld column.
The google_index feature denotes if the URL is indexed in google search console or not. In this dataset, all the URLs are google indexed and have a value of 1.
Exploratory Data Analysis (EDA)
In this step, we will check the distribution of different features for all four classes of URLs.
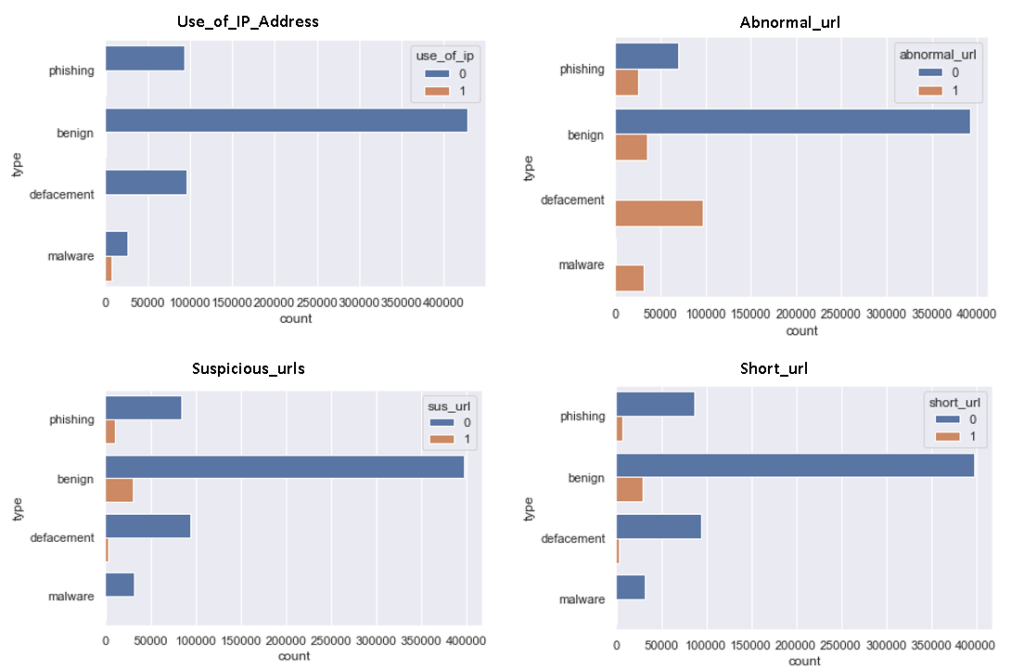
As we can observe from the above distribution of use_ip_address feature, only malware URLs have IP addresses. In the case of abnormal_url, defacement URLs have higher distribution.
From the distribution of suspicious_urls, it is clear that benign URLs have highest distribution while phishing URLs have a second highest distribution. As suspicious URLs consist of transaction and payment-related keywords and generally genuine banking or payment-related URLs consist of such keywords that’s why benign URLs have the highest distribution.
As per the short_url distribution, we can observe that benign URLs have the highest short URLs as we know that generally, we use URL shortening services for easily sharing long-length URLs.
Label Encoding
After that, the most important step is to label and encode the target variable (type) so that it can be converted into numerical categories 0,1,2, and 3. As machine learning algorithms only understand numeric target variable.
from sklearn.preprocessing import LabelEncoder lb_make = LabelEncoder() df["type_code"] = lb_make.fit_transform(df["type"])
Segregating Feature and Target variables
So, in the next step, we have created a predictor and target variable. Here predictor variables are the independent variables i.e., features of URL, and target variable type.
#Predictor Variables
# filtering out google_index as it has only 1 value
X = df[['use_of_ip','abnormal_url', 'count.', 'count-www', 'count@',
'count_dir', 'count_embed_domian', 'short_url', 'count-https',
'count-http', 'count%', 'count?', 'count-', 'count=', 'url_length',
'hostname_length', 'sus_url', 'fd_length', 'tld_length', 'count-digits',
'count-letters']]
#Target Variable
y = df['type_code']Training & Test Split
The next step is to split the dataset into train and test sets. We have split the dataset into 80:20 ratio i.e., 80% of the data was used to train the machine learning models, and the rest 20% was used to test the model.
As we know we have an imbalanced dataset. The reason for this is around 66% of the data has benign URLs, 5% malware, 14% phishing, and 15% defacement URLs. So after randomly splitting the dataset into train and test, it may happen that the distribution of different categories got disturbed which will highly affect the performance of the machine learning model. So to maintain the same proportion of the target variable stratification is needed.
This stratify parameter makes a split so that the proportion of values in the sample produced will be the same as the proportion of values provided to the parameter stratify.
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.2,shuffle=True, random_state=5)
So, now we are ready for the most awaited part which is Model Building !!!

Model building
In this step, we will build three tree-based ensemble machine learning models i.e., Light GBM, XGBoost, and Random Forest.
The code for building machine learning models is shared below.
# Random Forest Model
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100,max_features='sqrt')
rf.fit(X_train,y_train)
y_pred_rf = rf.predict(X_test)
print(classification_report(y_test,y_pred_rf,target_names=['benign', 'defacement','phishing','malware']))
score = metrics.accuracy_score(y_test, y_pred_rf)
print("accuracy: %0.3f" % score)
#XGboost
xgb_c = xgb.XGBClassifier(n_estimators= 100)
xgb_c.fit(X_train,y_train)
y_pred_x = xgb_c.predict(X_test)
print(classification_report(y_test,y_pred_x,target_names=['benign', 'defacement','phishing','malware']))
score = metrics.accuracy_score(y_test, y_pred_x)
print("accuracy: %0.3f" % score)
# Light GBM Classifier
lgb = LGBMClassifier(objective='multiclass',boosting_type= 'gbdt',n_jobs = 5,
silent = True, random_state=5)
LGB_C = lgb.fit(X_train, y_train)
y_pred_lgb = LGB_C.predict(X_test)
print(classification_report(y_test,y_pred_lgb,target_names=['benign', 'defacement','phishing','malware']))
score = metrics.accuracy_score(y_test, y_pred_lgb)
print("accuracy: %0.3f" % score)Model evaluation & comparison
After fitting the model, as shown above, we have made predictions on the test set. The performance of Light GBM, XGBoost, and Random Forest are shown below.
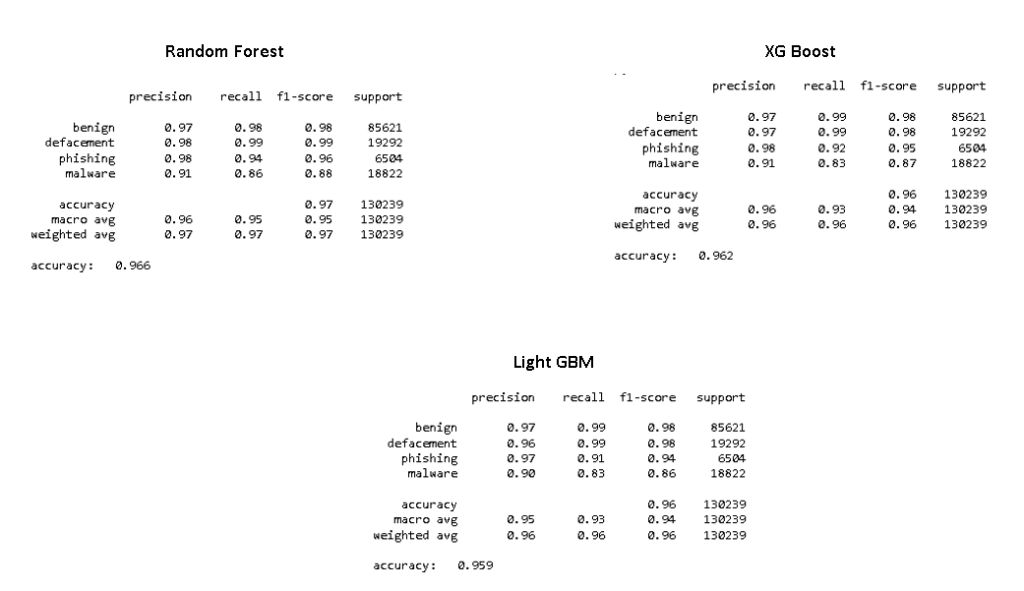
From the above result, it is evident that Random Forest shows the best performance in terms of test accuracy as it attains the highest accuracy of 96.6% with a higher detection rate for benign, defacement, phishing, and malware.
So based on the above performance, we have selected Random Forest as our main model for detecting malicious URLs and in the next step, we will also plot the feature importance plot.
Feature Importance
After selecting our model i.e., Random Forest, next, we will be checking highly contributing features. The code for plotting feature importance plot.
feat_importances = pd.Series(rf.feature_importances_, index=X_train.columns) feat_importances.sort_values().plot(kind="barh",figsize=(10, 6))
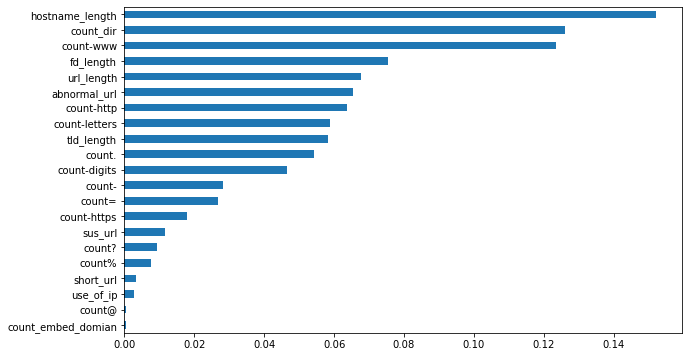
From the above plot, we can observe that the top 5 features for detecting malicious URLs are hostname_length, count_dir, count-www, fd_length, and url_length.
Model prediction
In this final step, we will predict malicious URLs using our best-performed model i.e., Random Forest.
The code for predicting raw URLs using our saved model is given below:
def main(url):
status = []
status.append(having_ip_address(url))
status.append(abnormal_url(url))
status.append(count_dot(url))
status.append(count_www(url))
status.append(count_atrate(url))
status.append(no_of_dir(url))
status.append(no_of_embed(url))
status.append(shortening_service(url))
status.append(count_https(url))
status.append(count_http(url))
status.append(count_per(url))
status.append(count_ques(url))
status.append(count_hyphen(url))
status.append(count_equal(url))
status.append(url_length(url))
status.append(hostname_length(url))
status.append(suspicious_words(url))
status.append(digit_count(url))
status.append(letter_count(url))
status.append(fd_length(url))
tld = get_tld(url,fail_silently=True)
status.append(tld_length(tld))
return status
# predict function
def get_prediction_from_url(test_url):
features_test = main(test_url)
# Due to updates to scikit-learn, we now need a 2D array as a parameter to the predict function.
features_test = np.array(features_test).reshape((1, -1))
pred = lgb.predict(features_test)
if int(pred[0]) == 0:
res="SAFE"
return res
elif int(pred[0]) == 1.0:
res="DEFACEMENT"
return res
elif int(pred[0]) == 2.0:
res="PHISHING"
return res
elif int(pred[0]) == 3.0:
res="MALWARE"
return res
# predicting sample raw URLs
urls = ['titaniumcorporate.co.za','en.wikipedia.org/wiki/North_Dakota']
for url in urls:
print(get_prediction_from_url(url))
Conclusion
In this article, we have demonstrated a machine learning approach to detect Malicious URLs. We have created 22 lexical features from raw URLs and trained three machine learning models XG Boost, Light GBM, and Random forest. Further, we have compared the performance of the 3 machine learning models and found that Random forest outperformed others by attaining the highest accuracy of 96.6%. By plotting the feature importance of Random forest we found that hostname_length, count_dir, count-www, fd_length, and url_length are the top 5 features for detecting the malicious URLs. At last, we have coded the prediction function for classifying any raw URL using our saved model i.e., Random Forest.
The full code demonstrated in this article is available at this Git repo.
Thank you for reading! Feel free to share your thoughts and ideas.
this model is not predicting accurately
training split occurs error how to solve pls help me
In Segregating Feature and Target variables section
instead of writing y=df[‘type_code’]
copy the entire columns from X and paste it inside of
y=df[‘(paste here)’]
PASTE THIS BELOW
y = malacious_dataset[[‘use_of_ip’,’abnormal_url’, ‘count.’, ‘count-www’, ‘count@’,
‘count_dir’, ‘count_embed_domian’, ‘short_url’, ‘count-https’,
‘count-http’, ‘count%’, ‘count?’, ‘count-‘, ‘count=’, ‘url_length’,
‘hostname_length’, ‘sus_url’, ‘fd_length’, ‘tld_length’, ‘count-digits’,
‘count-letters’]]
this was very helpfull for me , I realised an other model of Logestic Regression and I got the accuracy = 87% , thank you
Thanks Massa for liking the content. Stay in touch for more such content. If you also want to contribute in this website, do visit our guest post submission page.https://wisdomml.in/guest-post-idea-submission/