
Table of Contents
In this article, we will demonstrate how we can build a Natural Language Processing (NLP) based web application consisting of advanced text summarization, named entity recognizer, sentiment analysis, question answering, and text completion. For building this web app, we have used spacy-streamlit library which is a very effective package for visualizing the Spacy model and building an interactive web app with Streamlit.
This NLP web app is a one-place solution for 5 key NLP tasks. This is a two-part tutorial series, first part consists of building a web app whereas in the second part we will deploy it on streamlit sharing platform using Github repo.
So, let’s start building the web app. For building the web app we need to install some python libraries. Before installing any package/library in our main anaconda environment we recommend creating a virtual environment in python and installing all the libraries in that environment. In that way, we can easily deploy our app by generating a requirements.txt file (containing all the dependencies) from our virtual environment.
For creating a virtual environment in windows, we have to run the following commands on windows terminal/cmd.
python -m venv virtual_envIn the above command virtual_env is the name of the virtual environment. To activate the virtual environment we have to write the following command:
C:/>virtual_env\Scripts\activate.batInstallation
So, now we will install some essential python libraries for building the NLP web app.
pip install spacy-streamlitNote: We need to install spacy with transformer model
pip install -U pip setuptools wheel
pip install -U spacy
python -m spacy download en_core_web_trfWe also need to install streamlit for building a web app
pip install streamlitApart from that we also need to install hugging face transformers for NLP tasks such as summarization, sentiment analysis, question answering, and automatic text completion.
pip install transformersAfter installing all the above packages we proceed toward the actual coding part. For building an app using streamlit we need to create one app.py file where our main code will reside.
We will break down the code into multiple parts so that we can understand the code part by part. First, we will import important packages:
import streamlit as st from time import sleep from stqdm import stqdm # for getting animation after submit event import pandas as pd from transformers import pipeline import json import spacy import spacy_streamlit
After importing libraries we will design a web page using streamlit. In our main python file app.py we will call our pre-trained model and also design a basic web page using streamlit library.
The design code of the web page is shown below:
def draw_all(
key,
plot=False,
):
st.write(
"""
# NLP Web App
This Natural Language Processing Based Web App can do anything u can imagine with Text. 😱
This App is built using pretrained transformers which are capable of doing wonders with the Textual data.
```python
# Key Features of this App.
1. Advanced Text Summarizer
2. Named Entity Recognition
3. Sentiment Analysis
4. Question Answering
5. Text Completion
```
"""
)
with st.sidebar:
draw_all("sidebar")
def main():
st.title("NLP Web App")
menu = ["--Select--","Summarizer","Named Entity Recognition",
"Sentiment Analysis","Question Answering","Text Completion"]
choice = st.sidebar.selectbox("Choose What u wanna do !!", menu)
if choice=="--Select--":
st.write("""
This is a Natural Language Processing Based Web App that can do
anything u can imagine with the Text.
""")
st.write("""
Natural Language Processing (NLP) is a computational technique
to understand the human language in the way they spoke and write.
""")
st.write("""
NLP is a sub field of Artificial Intelligence (AI) to understand
the context of text just like humans.
""")
st.image('banner_image.jpg')
if __name__ == '__main__':
main()After writing the code below, we have to check our web app appearance by running the app using streamlit server.
Below command need to be executed in the windows terminal in a virtual environment and into the project folder where this app.py resides.
(streamlit_env) C:\Users\Sid32\Desktop\Complete_NLP>streamlit run app.pyAfter running the above command the web app can be viewed at http://localhost:8501.

As we can see in the screenshot the web page is divided into two parts sidebar containing the text and the sidebar whereas the middle section contains the image and text.
The sidebar section was created by writing code using streamlit object st. sidebar. In the code we have created a sidebar by writing with st.sidebar(): and under this, we have called the draw_all function which contains the text written in the sidebar and drop-down menu.
For middle section we have written text under main() function using st.write() and placed the image using st.image() that’s it. By writing just this code our basic skeleton of the web app is ready now e have to code the main part i.e., our NLP tasks.
For coding all the five NLP functionalities we have called our pre-trained models based on if condition in the main function. The code snippet for the same is shared below:
elif choice=="Summarizer":
st.subheader("Text Summarization")
st.write(" Enter the Text you want to summarize !")
raw_text = st.text_area("Your Text","Enter Your Text Here")
num_words = st.number_input("Enter Number of Words in Summary")
if raw_text!="" and num_words is not None:
num_words = int(num_words)
summarizer = pipeline('summarization')
summary = summarizer(raw_text, min_length=num_words,max_length=50)
s1 = json.dumps(summary[0])
d2 = json.loads(s1)
result_summary = d2['summary_text']
result_summary = '. '.join(list(map(lambda x: x.strip().capitalize(),
result_summary.split('.'))))
st.write(f"Here's your Summary : {result_summary}")The above code starts from the elif condition in the main() function as we are showing default text and image when the choice of the dropdown is “—select—“ i.e., if condition.
Now we will discuss each part one by one.
1. Advanced Summarizer
In the first part, we coded Summarizer using hugging face transformers as hugging face transformers are very efficient and generate an abstractive summary of the original text.
The abstractive summary is the concise form of source text which is the advanced form of summary in which summary contains the paraphrasing of the main contents of the source text, using a vocabulary set other than the original text. This type of summary is generally humans do by understanding the context of the original text.
For using the transformers for summarization tasks we have called them using pipeline function which is defined under transformers.
from transformers import pipeline
summarizer = pipeline('summarization')
summary = summarizer(raw_text, max_length=50)In the summarizer we have two main arguments in the first place we need to pass the actual text, then the maximum length of the summarizer which we are asking from the user and decides the actual length of the summary text.
In the original text, we have passed the following text about Albert Einstein from Wikipedia.

“Albert Einstein (/ˈaɪnstaɪn/ EYEN-styne;[4] German: [ˈalbɛʁt ˈʔaɪnʃtaɪn] (About this soundlisten); 14 March 1879 – 18 April 1955) was a German-born theoretical physicist,[5] widely acknowledged to be one of the greatest physicists of all time. Einstein is known for developing the theory of relativity, but he also made important contributions to the development of the theory of quantum mechanics. Relativity and quantum mechanics are together the two pillars of modern physics.[3][6] His mass–energy equivalence formula E = mc2, which arises from relativity theory, has been dubbed “the world’s most famous equation”.[7] His work is also known for its influence on the philosophy of science.[8][9] He received the 1921 Nobel Prize in Physics “for his services to theoretical physics, and especially for his discovery of the law of the photoelectric effect”,[10] a pivotal step in the development of quantum theory. His intellectual achievements and originality resulted in “Einstein” becoming synonymous with “genius”.[11]
In 1905, a year sometimes described as his annus mirabilis (‘miracle year’), Einstein published four groundbreaking papers.[12] These outlined the theory of the photoelectric effect, explained Brownian motion, introduced special relativity, and demonstrated mass-energy equivalence. Einstein thought that the laws of classical mechanics could no longer be reconciled with those of the electromagnetic field, which led him to develop his special theory of relativity. He then extended the theory to gravitational fields; he published a paper on general relativity in 1916, introducing his theory of gravitation. In 1917, he applied the general theory of relativity to model the structure of the universe.[13][14] He continued to deal with problems of statistical mechanics and quantum theory, which led to his explanations of particle theory and the motion of molecules. He also investigated the thermal properties of light and the quantum theory of radiation, which laid the foundation of the photon theory of light. However, for much of the later part of his career, he worked on two ultimately unsuccessful endeavors. First, despite his great contributions to quantum mechanics, he opposed what it evolved into, objecting that nature “does not play dice”.[15] Second, he attempted to devise a unified field theory by generalizing his geometric theory of gravitation to include electromagnetism. As a result, he became increasingly isolated from the mainstream of modern physics.
Einstein was born in the German Empire, but moved to Switzerland in 1895, forsaking his German citizenship (as a subject of the Kingdom of Württemberg)[note 1] the following year. In 1897, at the age of 17, he enrolled in the mathematics and physics teaching diploma program at the Swiss Federal polytechnic school in Zürich, graduating in 1900. In 1901 he acquired Swiss citizenship, which he kept for the rest of his life, and in 1903 he secured a permanent position at the Swiss Patent Office in Bern. In 1905, he was awarded a PhD by the University of Zurich. In 1914, Einstein moved to Berlin in order to join the Prussian Academy of Sciences and the Humboldt University of Berlin. In 1917, Einstein became director of the Kaiser Wilhelm Institute for Physics; he also became a German citizen again – Prussian this time.
In 1933, while Einstein was visiting the United States, Adolf Hitler came to power. Einstein did not return to Germany because he objected to the policies of the newly elected Nazi-led government.[16] He settled in the United States and became an American citizen in 1940.[17] On the eve of World War II, he endorsed a letter to President Franklin D. Roosevelt alerting him to the potential German nuclear weapons program and recommending that the US begin similar research. Einstein supported the Allies, but generally denounced the idea of nuclear weapons.”
The summary generated by our web app:
“Albert einstein was one of the greatest physicists of all time. He was born in germany, but moved to switzerland in 1895, forsaking his german citizenship. In 1905, he published four groundbreaking papers outlining the theory of the photoelectric effect, explained brownian motion, introduced special relativity, and demonstrated mass-energy equivalence. He received the 1921 nobel prize in physics for his contributions to quantum theory.”
As we can observe from the above summary that our model has nicely summarized the actual context of the original text in the summary.
2. Named Entity Recognizer
In the next part, we have implemented the Named Entity Recognizer using Spacy and visualized the entities using spacy_streamlit.visualize_ner() function.
elif choice=="Named Entity Recognition":
nlp = spacy.load("en_core_web_trf")
st.subheader("Text Based Named Entity Recognition")
st.write(" Enter the Text below To extract Named Entities !")
raw_text = st.text_area("Your Text","Enter Text Here")
if raw_text !="Enter Text Here":
doc = nlp(raw_text)
for _ in stqdm(range(50), desc="Please wait a bit. The model is fetching the results !!"):
sleep(0.1)
spacy_streamlit.visualize_ner(doc, labels=nlp.get_pipe("ner").labels, title= "List of Entities")The output of the web app based on the text is shown below:
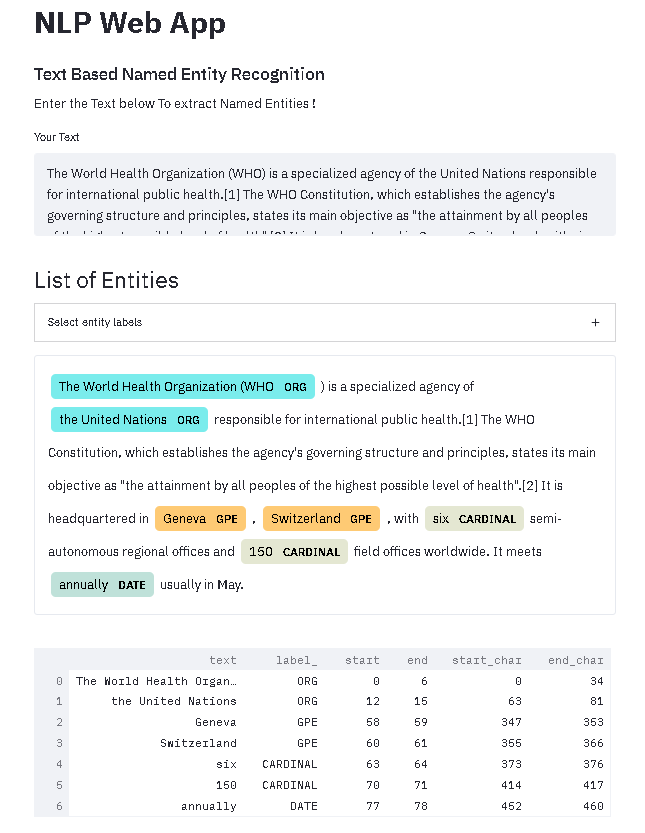
From the above output, we can observe that our web app successfully extracted and highlighted entities ORG, GPE, CARDINAL, and DATE from the text.
3. Sentiment Analysis
In the next part, we have implemented sentiment analysis using a transformer. The code for the implementation is shown below:
elif choice=="Sentiment Analysis":
st.subheader("Sentiment Analysis")
sentiment_analysis = pipeline("sentiment-analysis")
st.write(" Enter the Text below To find out its Sentiment !")
raw_text = st.text_area("Your Text","Enter Text Here")
if raw_text !="Enter Text Here":
result = sentiment_analysis(raw_text)[0]
sentiment = result['label']
for _ in stqdm(range(50), desc="Please wait a bit. The model is fetching the results !!"):
sleep(0.1)
if sentiment =="POSITIVE":
st.write("""# This text has a Positive Sentiment. 🤗""")
elif sentiment =="NEGATIVE":
st.write("""# This text has a Negative Sentiment. 😤""")
elif sentiment =="NEUTRAL":
st.write("""# This text seems Neutral ... 😐""")The input and output of the web app for the sentiment analysis task are shared below image.

The text for checking the sentiment is taken from the amazon website of a particular electronic product which has a positive review and the web app is also predicted positive sentiment.
4. Question Answering
In the next part, we have implemented question answering using transformers. The code for the implementation is shared below:
elif choice=="Question Answering":
st.subheader("Question Answering")
st.write(" Enter the Context and ask the Question to find out the Answer !")
question_answering = pipeline("question-answering")
context = st.text_area("Context","Enter the Context Here")
question = st.text_area("Your Question","Enter your Question Here")
if context !="Enter Text Here" and question!="Enter your Question Here":
result = question_answering(question=question, context=context)
s1 = json.dumps(result)
d2 = json.loads(s1)
generated_text = d2['answer']
generated_text = '. '.join(list(map(lambda x: x.strip().capitalize(), generated_text.split('.'))))
st.write(f" Here's your Answer :\n {generated_text}")Question answering has two main parts first is the context which is required to consume for answering questions. So based on this question we have to ask some questions just like reading comprehension we read some big text and then we have to answer the questions based on the comprehension.
Therefore in the question answering pipeline, we have to pass a context and the question and the pre-trained transformer will generate the answer based on the context. This is the most advanced application of NLP as it requires a deep understanding of the text for answering questions.
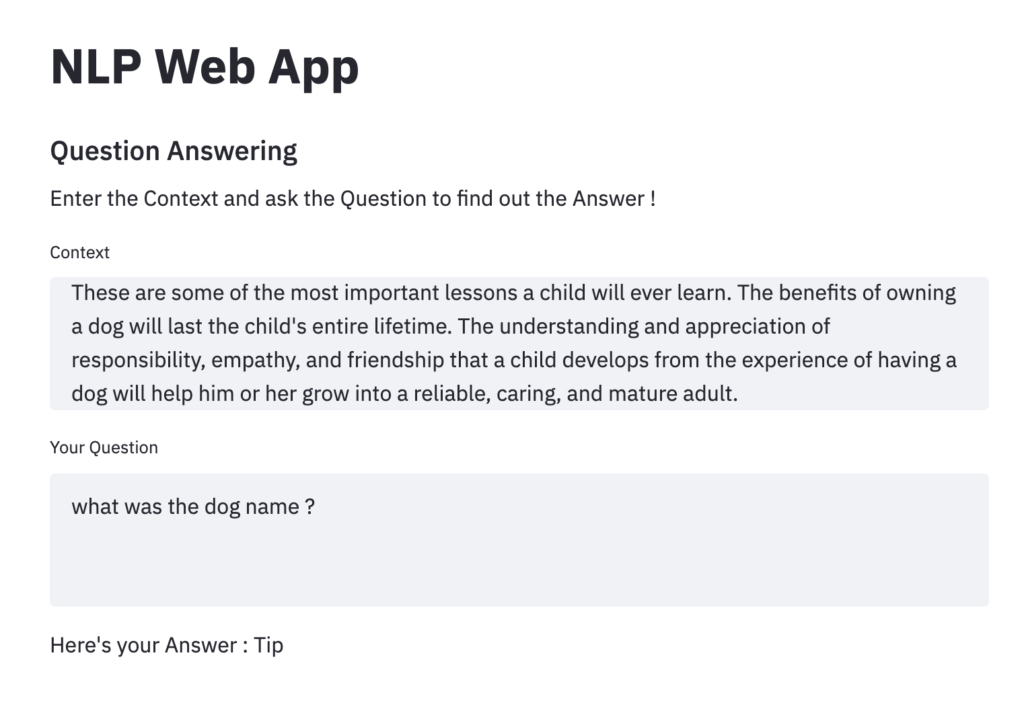
For testing question answering we have taken a quite complex reading comprehension from this link and the results based on the passage are shown in the above screenshot.
5. Text Completion
In this part, we have implemented automated text completion using transformers. In this task, we need to pass the incomplete text to the transformer model and it will complete the text automatically. In the pipeline, we have to write “text-generation” for calling the text completion model.
elif choice=="Text Completion":
st.subheader("Text Completion")
st.write(" Enter the uncomplete Text to complete it automatically using AI !")
text_generation = pipeline("text-generation")
message = st.text_area("Your Text","Enter the Text to complete")
if message !="Enter the Text to complete":
generator = text_generation(message)
s1 = json.dumps(generator[0])
d2 = json.loads(s1)
generated_text = d2['generated_text']
generated_text = '. '.join(list(map(lambda x: x.strip().capitalize(), generated_text.split('.'))))
st.write(f" Here's your Generate Text :\n {generated_text}")The screenshot of text completion in the web app is shown in the below image.
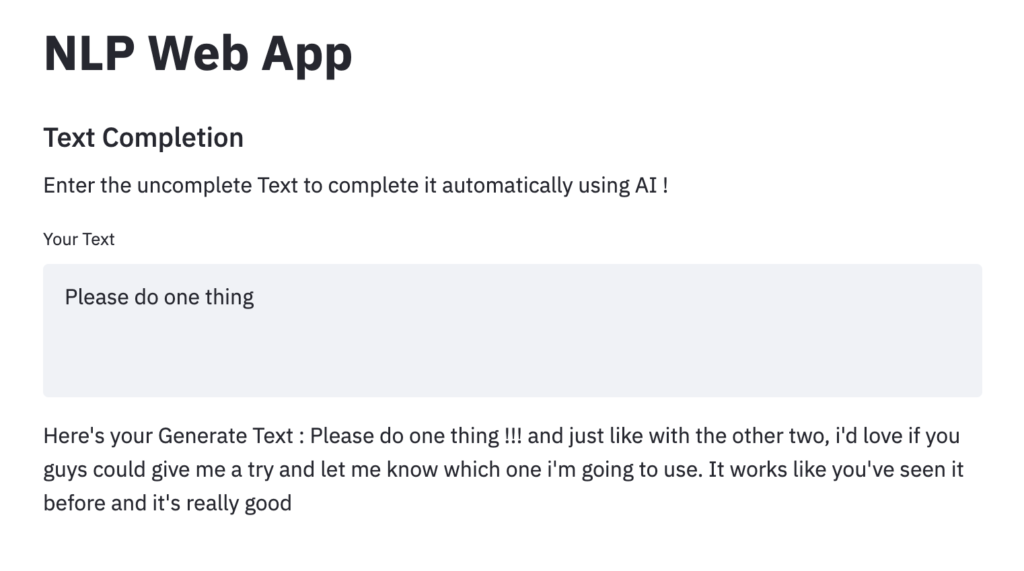
As we can see that the web app has successfully completed the text with meaningful context.
In all the five NLP tasks we get the response in JSON format and we have extracted the desired response as shown in the code snippets.
The full code is available in this Git repo.
Thank you for reading! Feel free to share your thoughts and ideas.