
Table of Contents
Natural Language Processing (NLP) has become increasingly popular in recent years, with companies utilizing it to automate customer service, improve search engines, and analyze sentiment.
As such, it is no surprise that job interviews for positions that require NLP knowledge and skills are becoming more common.
In this article, we will provide 30+ commonly asked NLP interview questions and their answers to help you prepare for your next interview.
1. What is NLP?
NLP is a subfield of computer science and artificial intelligence that focuses on the interaction between computers and human language. Its goal is to enable computers to understand, interpret, and generate human language. NLP has applications in a wide range of fields, including machine translation, sentiment analysis, and speech recognition.
2. What are the key components of NLP?
The key components of NLP include tokenization, stemming, lemmatization, named entity recognition, part-of-speech (PoS) tagging, sentiment analysis, topic modeling, and word embedding. These techniques allow computers to understand and process human language in a way that was previously impossible.
3. What is tokenization in NLP?
Tokenization is the process of breaking down the text into individual words, phrases, or other meaningful elements. The resulting tokens can then be used for further analysis or processing.
For example, the sentence “The quick brown fox jumped over the lazy dog” would be tokenized into :
“The”, “quick”, “brown”, “fox”, “jumped”, “over”, “the”, “lazy”, and “dog”.
To know more details about tokenization read our article.
4. What is stemming in NLP?
Stemming is the process of reducing words to their root form, or stem. This is done by removing suffixes and prefixes from the word. For example, the stem of the word “running” is “run”.
Stemming is useful in NLP because it allows computers to recognize different forms of the same word as being the same, which can simplify analysis.
To know more details about Stemming read our article.
5. What is lemmatization in NLP?
Lemmatization is similar to stemming, but instead of simply reducing words to their root form, it maps words to their base or dictionary form. For example, the lemma of “was” is “be”.
Lemmatization is a more advanced technique than stemming because it takes into account the context of the word, which can improve accuracy.
To know more details about Lemmatization read our article
6. What is named entity recognition in NLP?
Named entity recognition is the process of identifying and classifying named entities in text, such as people, organizations, and locations.
7. What is sentiment analysis in NLP?
Sentiment analysis is the process of identifying the emotional tone of a piece of text. This can be used to analyze customer feedback, social media posts, and more.
8. What is topic modeling in NLP?
Topic modeling is the process of identifying the main themes or topics in a piece of text. This can be used to analyze large sets of documents, such as news articles or academic papers.
9. What is word embedding in NLP?
Word embedding is the process of representing words as vectors in a high-dimensional space. This can be used to analyze word relationships and similarities, and is often used in tasks such as language translation and sentiment analysis.
10. What is the difference between supervised and unsupervised learning in NLP?
Supervised learning is a type of machine learning where the model is trained on labeled data, meaning data that has already been tagged or classified with a specific outcome. This is commonly used in tasks such as sentiment analysis, where the model is trained on a set of labeled data to predict the sentiment of new, unlabeled data.
Unsupervised learning, on the other hand, involves training the model on unlabeled data and allowing it to find patterns or groupings on its own. This is often used in tasks such as topic modeling, where the model is trained on a set of documents and identifies the main topics or themes present in the data.
11. Why do we use RNN in NLP?
RNN (Recurrent Neural Networks) is a type of computer program that can help us understand and work with human language in really cool ways!
Imagine you are reading a storybook with a talking robot character. The robot needs to understand what the other characters are saying so it can respond appropriately. That’s where RNN comes in! It helps the robot understand the story by looking at the words in the story and figuring out what they mean.
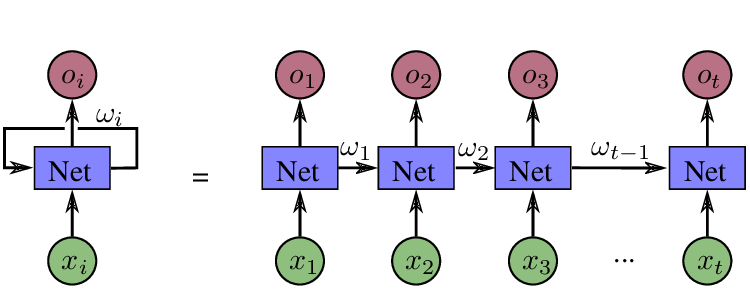
RNN is really helpful in NLP (Natural Language Processing) because it can remember things from earlier in the story and use that information to understand what’s happening now. Just like how you can remember things that happened earlier in the day and use that information to understand what’s happening now.
So, RNN is a really powerful tool in NLP that helps computers understand human language better by looking at the words and remembering important information from earlier in the conversation. It’s kind of like having a really smart robot friend who can talk to you and understand everything you say!
12. Why RNN is better than CNN for NLP?
RNN (Recurrent Neural Networks) and CNN (Convolutional Neural Networks) are two types of neural networks that are often used in NLP (Natural Language Processing). While both can be useful for certain tasks, RNN is generally considered better than CNN for NLP, for several reasons.
One reason is that RNN is designed to work with sequences of data, such as sentences or paragraphs, which is important in NLP where the order of words and phrases is critical to understanding the meaning of a text. RNN can process this sequential data in a way that allows it to remember information from earlier in the sequence and use that information to better understand the context of the text.
On the other hand, CNN is designed to work with structured data, such as images or audio, and is not as effective at processing sequential data. While CNN can be used in NLP for tasks such as text classification, it is often less effective than RNN at tasks such as language modeling and speech recognition.
Another reason why RNN is better than CNN for NLP is that RNN has a form of memory, called a “hidden state,” which allows it to remember information from earlier in the sequence and use it to make predictions about future data. This is important in NLP, where understanding the context of a text is critical to accurately interpreting its meaning.
13. Why do we use LSTM in NLP?
LSTM (Long Short-Term Memory) is a type of Recurrent Neural Network (RNN) that is frequently used in Natural Language Processing (NLP) due to its unique properties and benefits.
One of the main advantages of LSTMs in NLP is their ability to retain important information for a longer period of time than other types of RNNs. This is critical in NLP because understanding the context of a text is essential for the accurate interpretation of its meaning. By retaining important information for a longer period of time, LSTMs can better comprehend the overall meaning of a text.
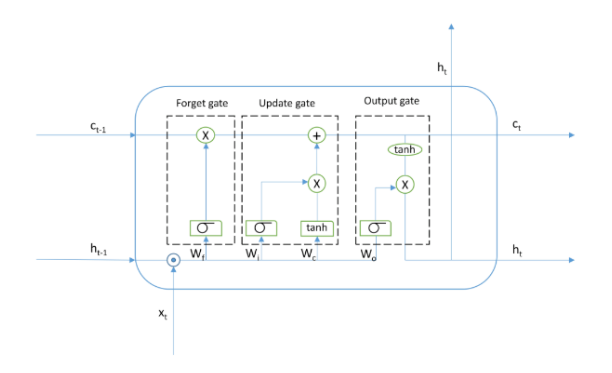
Another benefit of LSTMs is their ability to recognize patterns and relationships in sequential data. This is important in NLP because the order of words and phrases is crucial for understanding the meaning of a text. LSTMs can learn these patterns and relationships in a way that enables them to make accurate predictions about future data.
Furthermore, LSTMs can handle variable-length input sequences. This is crucial in NLP because texts can vary significantly in length and complexity. LSTMs can process input sequences of any length and use the information they learn to make precise predictions.
In summary, LSTMs are an important tool in NLP that can help computers better understand and interpret human language. By retaining important information, recognizing patterns, and handling variable-length input sequences, LSTMs have the potential to improve the accuracy and effectiveness of NLP models.
14. Can we apply CNN to text data?
Yes, it is possible to use CNN (Convolutional Neural Networks) in Natural Language Processing (NLP) for text data, but it requires a specific approach.
CNNs were originally designed for image recognition tasks, but researchers have modified them to work with text data. One approach is to represent the text as a matrix of word embeddings, where each word is assigned a dense vector of a fixed length. The matrix can be treated like an image, with each row representing a “channel” and each column representing a “time step”. Filters can then be applied across the “time steps” to identify patterns in the text.
Another approach is to use a 1D-CNN architecture that applies filters directly to the one-dimensional sequence of word embeddings. This can be useful for detecting features such as sentiment and identifying patterns such as n-grams.
However, it is important to note that CNNs are not as commonly used in NLP as other techniques like RNNs and LSTMs. CNNs are typically used in specific tasks such as text classification and sentiment analysis. While they can be effective for these tasks, it is important to choose the appropriate approach based on the specific needs of the project.
15. What are some common NLP libraries and tools?
Some common NLP libraries and tools include NLTK (Natural Language Toolkit), spaCy, Gensim, Stanford NLP, and OpenNLP. These libraries and tools provide a range of NLP functionality, such as tokenization, stemming, lemmatization, PoS tagging, parsing, and named entity recognition.
16. What are transformers in NLP?
The Transformer model consists of an encoder and a decoder. The encoder receives input text and converts it into a series of hidden representations, while the decoder uses these representations to generate an output text sequence.
The key innovation of the Transformer is its self-attention mechanism, which allows the model to focus on different parts of the input text at different times to capture long-range dependencies between words. The self-attention mechanism computes attention weights for each word based on its relationship with every other word in the sequence. This helps the model concentrate on important words and ignore irrelevant ones.
To enhance training stability and convergence, the Transformer employs residual connections and layer normalization. These techniques prevent the model from getting stuck in local optima and ensure meaningful representation learning.
The Transformer architecture has found many applications in NLP, including language translation, language modeling, and text generation. It has surpassed previous state-of-the-art models and is a significant advancement in the field of NLP.
17. What is one of the most common problems with training RNNs and LSTMs?
One of the most common problems with training RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory) is the issue of vanishing or exploding gradients.
During training, the gradients used to update the weights of the network are calculated by backpropagating through the network. However, in RNNs and LSTMs, the gradients can become very small (vanishing gradients) or very large (exploding gradients) as they are backpropagated through the network. This can cause the network to have difficulty learning long-term dependencies and result in slow or unstable training.
To address this issue, several techniques have been developed, such as gradient clipping, weight initialization, and using alternative activation functions such as ReLU (Rectified Linear Unit) or its variants. Another popular approach is to use gated architectures such as LSTMs or GRUs (Gated Recurrent Units), which are designed to mitigate the vanishing gradient problem by allowing the network to selectively retain or discard information over time.
Overall, addressing the vanishing and exploding gradient problem is crucial for training effective RNN and LSTM models in NLP, and researchers continue to develop new techniques to improve the training stability and performance of these networks.
18. What is the difference between NLP and natural language understanding (NLU)?
NLP (Natural Language Processing) and NLU (Natural Language Understanding) are two subfields of AI that deal with human language, but they differ in their specific focus and goals.
NLP is concerned with the mechanics of language processing, such as speech recognition, machine translation, and sentiment analysis. The goal of NLP is to enable machines to understand and interpret human language, which can help them perform a wide range of tasks related to language.
On the other hand, NLU is a more specialized subset of NLP that focuses on the meaning and context of language. This involves tasks such as named entity recognition, text classification, and information extraction. The goal of NLU is to enable machines to accurately interpret and respond to human input, which requires a deeper understanding of the meaning and context of language.
Despite their differences, both NLP and NLU are important subfields of AI that are helping to drive advancements in natural language processing and communication. These technologies are used in various applications, such as chatbots and virtual assistants, to improve communication and efficiency in a variety of industries and contexts.
As NLP and NLU continue to evolve, we can expect to see even more impressive applications and use cases in the future. With these technologies, machines will be able to understand and interpret human language in more sophisticated and nuanced ways, enabling new levels of communication and interaction between humans and machines.
19. What is the difference between NLP and natural language generation (NLG)?
NLP and NLG are two subfields of artificial intelligence that deal with human language, but they have distinct goals and applications. NLP aims to teach computers to understand and interpret human language, while NLG aims to teach computers to produce human-like language that is coherent and grammatically correct.
NLP is all about analyzing human language for various purposes, such as sentiment analysis or information extraction. This means that NLP systems are designed to understand the structure and meaning of language, even when it is complex or ambiguous. This can be a challenging task, as human language can be nuanced and layered.
On the other hand, NLG is all about generating human-like language. This means that NLG systems are designed to produce language that is natural-sounding and grammatically correct. This can be a challenging task, as human language can be full of quirks and idiosyncrasies.
Despite their differences, NLP and NLG share some common tools and techniques. For example, both use machine learning algorithms to identify patterns and relationships in large datasets. This allows models to learn and improve over time, which is important for both understanding and generating human language.
Overall, NLP and NLG are both exciting areas of research that are helping to drive advancements in natural language processing and communication. As these fields continue to evolve, we can expect to see even more impressive applications and use cases in the future.
20. What is the importance of language modeling in NLP?
Language modeling is the process of predicting the likelihood of a sequence of words occurring in a given context. This is important in NLP because it allows models to generate coherent and grammatically correct sentences, and can be used in tasks such as language translation and text generation.
21. What is the purpose of the bag-of-words model in NLP?
The bag-of-words model is a technique used to represent text as a collection of individual words, ignoring grammar and word order. This is useful in NLP because it allows models to analyze large datasets quickly and efficiently, without the need to consider the context or structure of the text.
To know more details about Lemmatization read our article.
22. What are stopwords in NLP?
In Natural Language Processing (NLP), stopwords are words that are commonly used in a language but are generally considered to have little or no meaning in the context of a specific sentence or document. Examples of stopwords in English include “the,” “a,” “an,” “and,” “in,” and “of.”
Stopwords can often be ignored or removed from text data when analyzing it, as they do not add much meaning to the overall text. Removing stopwords can help to reduce noise and improve the accuracy of NLP models.
To know more about stopwords and their removal process read our detailed article.
23. What is TF-IDF in NLP?
TF-IDF (Term Frequency-Inverse Document Frequency) is a statistical measure used in Natural Language Processing (NLP) to evaluate the importance of a term in a document or collection of documents.
TF-IDF is calculated by multiplying the term frequency (TF) of a word in a document by the inverse document frequency (IDF) of the same word across a collection of documents. The term frequency component measures how frequently a term appears in a document, while the inverse document frequency component measures how unique or rare a term is across a collection of documents.
The term frequency is calculated by dividing the number of times a word appears in a document by the total number of words in the document. The inverse document frequency is calculated by taking the logarithm of the total number of documents divided by the number of documents containing the word.

The resulting TF-IDF score reflects the importance of a term in a particular document relative to its importance across the entire collection of documents. Terms that appear frequently in a single document but rarely in other documents are given higher weights, while common terms that appear frequently in many documents are given lower weights.
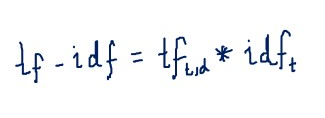
TF-IDF is commonly used in NLP applications such as search engines, text classification, and information retrieval to identify the most relevant and important documents or terms in a collection of text data.
24. What is Canonicalization in NLP?
Canonicalization is a process used in Natural Language Processing (NLP) to standardize words or phrases to a specific form. The purpose of canonicalization is to reduce the variability of text data and improve the accuracy of NLP models by treating different representations of the same concept as equivalent.
For instance, canonicalization can be used to convert different verb forms to their base form, such as converting “running,” “ran,” and “run” to “run.” It can also be used to convert different spellings of the same word to a standard form, such as converting “colour” to “color” or “favourite” to “favorite.”
There are several techniques for canonicalization, including lemmatization, stemming, and spell-checking. Lemmatization involves reducing words to their base or dictionary form, which helps to reduce the variability of text data and improve the accuracy of NLP models. Stemming, on the other hand, involves reducing words to their stem or root form. Spell-checking can also be used to identify and correct spelling errors in text data, which helps to improve the accuracy of NLP models.
To know more about canonicalization read our article.
25. What is Phonetic Hashing in NLP?
Phonetic hashing is a technique used in Natural Language Processing (NLP) to convert words or phrases into a compact, phonetic representation based on their sound. It can be useful in NLP applications where matching or clustering text based on its sound is more important than its spelling or meaning.
To know more about canonicalization read our article.
26. What is Poinwise Mutual Information in NLP?
Pointwise Mutual Information (PMI) is a statistical measure used in Natural Language Processing (NLP) to evaluate the correlation between two words in a text corpus. It measures the extent to which the occurrence of one word is dependent on the occurrence of another word. PMI can be positive, indicating a strong correlation, or negative, indicating a weak correlation. PMI is useful in NLP for identifying frequently co-occurring words, which can provide insights into the relationships between different concepts or topics. It can also be used to identify sentiment-bearing words in a text corpus by measuring their co-occurrence with positive or negative words.
27. How does the n-gram model work in NLP?
The n-gram model is a type of language model that predicts the likelihood of a sequence of n-words occurring in a given context. For example, a bigram model would predict the likelihood of a specific word occurring after another specific word. This can be used in tasks such as language modeling and speech recognition.
28. What is the purpose of part-of-speech tagging in NLP?
Part-of-speech tagging is the process of labeling each word in a sentence with its corresponding part of speech, such as noun, verb, or adjective. This is useful in NLP because it allows models to better understand the structure and meaning of a sentence, and can be used in tasks such as text classification and sentiment analysis.
29. How does the Hidden Markov Model (HMM) work in NLP?
The Hidden Markov Model is a statistical model used to predict the probability of a sequence of observations, based on a set of hidden states. In NLP, HMMs can be used for tasks such as speech recognition, where the model predicts the most likely sequence of words based on the audio input.
30. What is the purpose of dependency parsing in NLP?
Dependency parsing is the process of analyzing the relationships between words in a sentence, and identifying the dependencies between them. This is useful in NLP because it allows models to better understand the structure and meaning of a sentence, and can be used in tasks such as text summarization and information extraction.
31. What is the difference between shallow parsing and deep parsing in NLP?
Shallow parsing involves identifying the structure of a sentence at a high level, such as identifying noun phrases and verb phrases. Deep parsing, on the other hand, involves analyzing the sentence at a more granular level, such as identifying the subject and object of a sentence. Deep parsing is more complex and computationally expensive than shallow parsing, but can provide more detailed insights into the structure and meaning of a sentence.
32. What is Generative AI and why it is gaining too much traction now?
Generative AI is a type of artificial intelligence that can generate new content such as text, images, or music. This is achieved through machine learning algorithms that learn from large datasets and can then generate new content that is similar in style or content to the original dataset.
Generative AI is gaining traction now due to several reasons. First, advancements in deep learning and neural networks have made it easier to create more sophisticated generative models. These models can generate new content that is increasingly convincing and difficult to distinguish from human-generated content.
Second, the rise of big data has provided an abundance of training data for generative models to learn from. This has allowed generative AI to become more accurate and produce higher-quality content.
Third, the increasing availability of computing power has made it possible to train and run more complex generative models in real-time. This has enabled the creation of new applications for generative AI in areas such as creative industries, gaming, and marketing.
Finally, there is a growing interest in generative AI as a means of exploring and expanding the creative potential of artificial intelligence. As the technology continues to evolve, generative AI has the potential to unlock new forms of expression and creativity, and to enhance our understanding of the nature of human creativity itself.
33. What are the examples of Generative AI?
There are many examples of generative AI models, some of which include:
- GPT (Generative Pre-trained Transformer) – a language model developed by OpenAI that can generate natural language text.
- StyleGAN (Style-based Generative Adversarial Network) – a generative model developed by NVIDIA that can create high-quality images of human faces.
- DeepDream – a computer vision algorithm developed by Google that can generate trippy and surreal images from existing images.
- MuseNet – a generative model developed by OpenAI that can compose original music in a variety of styles.
- DALL-E – a generative model developed by OpenAI that can generate original images from text descriptions.
- GAN (Generative Adversarial Network) – is a type of neural network that can generate images, text, and even videos.
- WaveNet – a generative model developed by Google that can generate natural-sounding speech.
34. What is the conditional random field in NLP?
A Conditional Random Field (CRF) is a type of computer model that helps computers understand the language better. Specifically, it helps computers label words in a sentence or document with a tag that shows what kind of word it is. For example, a CRF might label the word “cat” in a sentence as a noun, or the word “run” as a verb.
What makes CRFs special is that they look at the whole sentence, not just each word by itself. This helps the model understand the context of each word and how it relates to the words around it. For example, the word “run” could be labeled as a verb or a noun depending on the context of the sentence.
CRFs are trained using lots of examples of tagged sentences or documents. The computer looks at these examples and learns how to label the words in new, unlabeled sentences or documents.
CRFs have been used for a variety of tasks in NLP, such as identifying people, places, and things in the text, and determining the part of speech of each word. By using context to make better predictions, CRFs help computers understand language more accurately.
35. What is the objective of topic modeling in NLP?
Topic modeling in Natural Language Processing (NLP) is the process of identifying and categorizing topics or themes within a collection of text documents. The objective of topic modeling is to analyze and extract meaningful insights from unstructured text data, which can help businesses and researchers make informed decisions based on the generated insights.
Topic modeling is an unsupervised machine learning technique that can analyze large volumes of text data to identify patterns and relationships that may not be immediately apparent to humans. One popular method of topic modeling is Latent Dirichlet Allocation (LDA), which identifies topics based on the distribution of words that co-occur in the documents.
Other techniques for topic modeling include Non-negative Matrix Factorization (NMF) and Hierarchical Dirichlet Processes (HDP). NMF is similar to LDA but uses a different mathematical approach, while HDP can discover an unlimited number of topics without requiring a fixed number beforehand.
Overall, the goal of topic modeling in NLP is to help businesses and researchers better understand their data and make informed decisions based on the insights gained from analyzing the data.
36. Explain the overall architecture of ChatGPT
The architecture of ChatGPT is based on the GPT-3 model, a state-of-the-art language model developed by OpenAI. It uses a multi-layer Transformer network with self-attention and feedforward neural networks to process natural language input and generate responses that are specific to a given task or domain. ChatGPT is trained on large datasets that are specific to the domain, allowing it to generate high-quality responses that are contextually relevant to the input.
The input text is first tokenized into individual words or subwords, which are then converted into numerical vectors. These vectors are fed into the Transformer network, which consists of multiple layers of self-attention and feedforward neural networks. The self-attention mechanism allows the model to capture the context and meaning of the text more accurately, while the feedforward neural networks generate a sequence of output tokens that represent the model’s response to the input text.
The architecture of ChatGPT is particularly effective at generating high-quality responses to natural language input because it is based on a large-scale language model that has been fine-tuned on specific domains and tasks. This allows it to produce responses that are more contextually relevant than other chatbot models, which may not be trained on as large or specific datasets. Furthermore, the self-attention mechanism used in the Transformer network enables the model to capture more nuanced aspects of the input text, such as sarcasm or irony, which can be challenging for other chatbot models.